
外观
面型工件有序上下料(并行化)视觉参数调整指南
入门引导
背景介绍
新增 "面型工件有序上下料(并行化)" 场景,作为面型有序的视觉加速方案,场景特点在于提升了视觉计算节拍,减少了实例生成过滤、姿态生成等中间计算过程,直接生成抓取点。
与其他场景视觉加速模式开启的方式不同,面型有序场景是通过新建作业。
作业场景选择
当前面型有序场景下,可选作业场景有两种,对比如下表。
| 工作流 | 面型有序上下料 | 面型有序上下料(并行化) | 备注 |
|---|---|---|---|
| 精度 | 高依赖点云密度与场景点云一致性 | 较高依赖图像特征、点云密度及场景点云的一致性 | / |
| 速度 | 较快(单实例) | 快(多实例) | 仅并行化可以输出场景全部有效结果 |
| 调参 | 中等需要有匹配调参经验 | 简单较简单固定(类似通用工件) | 并行化参数后续会隐藏部分大师类 |
| 适用性 | 强适用所有面型工件 | 较弱当前版本支持来料朝向不一致的情况 | 并行化已更新多模版模式,支持多个来料方向 |
| 模版制作难度 | 一般软件支持 | 较复杂当前版本需要使用脚本 | 后续并行化将模版制作并入PickWiz中 |
| 模版特点 | 参考 | 选取相机视野相对居中的完整场景实例点云 | / |
搭建项目
(1)新建一个面型工件有序上下料(并行化)项目(项目名称、项目地址可以自定义,项目名称不能有中文)
工件类型:面型工件(不是圆、圆柱、四边形,且正反面差异较小)
(2)相机、机器人配置
(3)添加工件
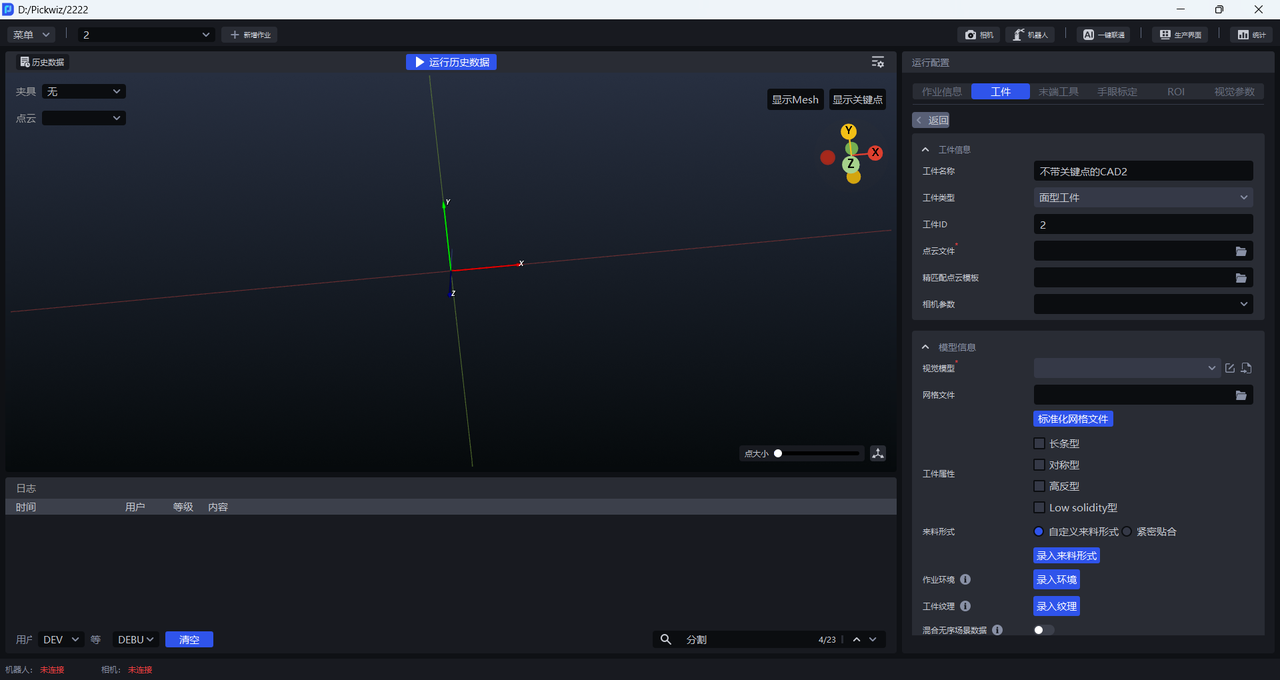
- 工件信息
工件名称可自定义,工件类型默认为标准工件且不可更改,工件ID可自定义,用于机器人抓取时自动切换工件
点云文件:工件点云模板,面型工件有序上下料(并行化)场景的点云文件较为特殊,制作方法请参照2.2.1模板文件路径
精匹配点云模板:用于精匹配
相机参数:不需要
- 模型信息
视觉模型:面型工件应用的2D识别方案是基于CAD的合成数据训练(一键联通)。不同的面型工件应用的视觉模型需要经过一键联通训练得到。
网格文件:一般上传工件CAD,为了摒弃一些噪声需要标准化网格文件,也可在点云模板制作标准化网格文件
工件属性:长条型、对称型、高反型、Low solidity型
来料形式:自定义来料形式------录入来料形式;紧密贴合------每行每列工件个数范围
作业环境:录入环境文件,一键联通中数据生成的环境会被自动替换为录入的环境,提高识别效果
工件纹理:录入工件纹理,一键联通中训练模型时会使用录入的工件纹理做数据增强,提高识别效果
混合无序场景数据:开启后,使用一键联通训练模型时,会同时生成无序场景和有序场景的合成数据用于模型训练,提高识别效果
模型最大识别数:默认20,根据场景需求修改
- 抓取点:根据工件设置抓取点
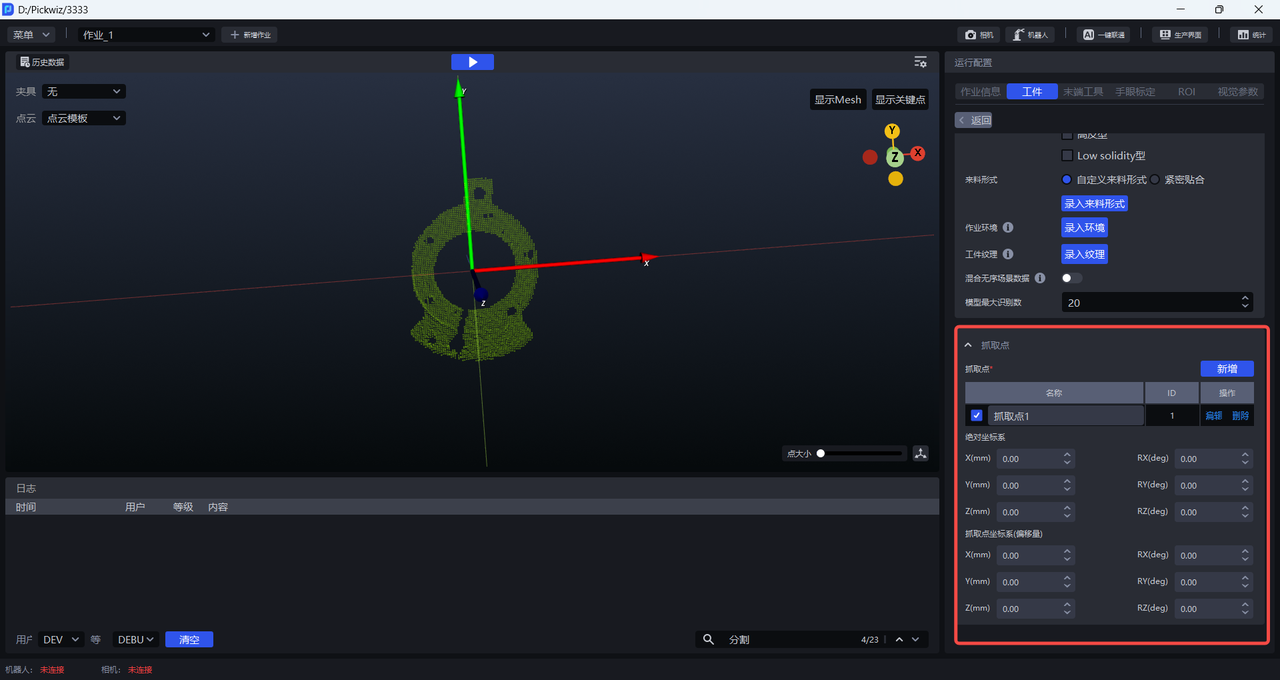
绝对坐标系:以初始点为原点,初始点是工件点云和CAD自带的。
抓取点坐标系(偏移量):以当前抓取点为原点。
(4)添加末端工具、手眼标定、ROI
(5)可选的功能选项:实例优化、碰撞检测、视觉分类、点云噪点滤除
实例优化:优化模型生成的实例,对实例掩膜进行处理。
碰撞检测:碰撞检测功能用于检测末端工具与容器的碰撞,过滤可能碰撞的抓取姿态。碰撞检测使用指南
视觉分类:用于识别同一工件的不同纹理、不同朝向等特征。视觉分类使用指南
点云噪点滤除:可导入工件的点云模板,来滤除实例工件点云的噪点。
视觉参数
- 2D识别:从实际场景中识别分割出实例
预处理:在进行实例分割之前,对2D图像进行处理(常用:填充深度图空洞&边缘增强&提取最上层纹理&去除roi3d外的图片背景)
实例分割:分割实例(缩放比例&置信度下限阈值&自动增强),加速可取消勾选 返回掩膜
点云生成:生成实例点云的方式,使用分割后的实例掩膜或包围盒生成实例点云/使用过滤后的实例掩膜或包围盒生成实例点云
实例过滤:对分割出的实例进行过滤
实例排序:对实例进行排序
- 3D计算:计算实例在相机坐标系下的姿态并生成抓取点
预处理:在计算抓取点之前,对3D点云进行预处理
姿态估计:计算实例在相机坐标系下的姿态(粗匹配、精匹配)并生成抓取点
- 抓取点处理:对抓取点进行过滤、调整、排序
抓取点过滤:对抓取点进行过滤
抓取点调整:对抓取点进行调整
抓取点排序:对抓取点进行排序
1. 2D识别
1.1 预处理
2D识别的预处理是在实例分割之前对2D图像进行处理
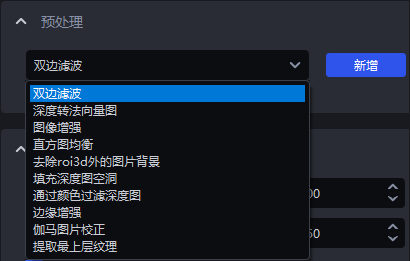
1.1.1 双边滤波
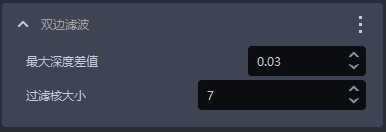
- 功能
基于双边滤波的图像平滑功能
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 最大深度差值 | 双边过滤的最大深度差值 | 0.03 | [0.01, 1] |
| 过滤核大小 | 双边过滤卷积核大小 | 7 | [1, 3000] |
1.1.2 深度转法向量图

- 功能
通过深度图计算像素法向量,并把图片转换成法向量图
1.1.3 图像增强
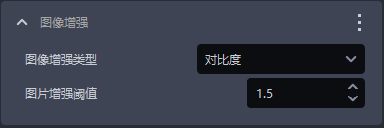
- 功能
常用图像增强,如色彩饱和度、对比度、亮度、锐利度
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 图像增强类型 | 对图像的某个元素进行增强 | 对比度 | 色彩饱和度、对比度、亮度、锐利度 |
| 图片增强阈值 | 对图像的某个元素增强多少 | 1.5 | [0.1, 100] |
1.1.4 直方图均衡

- 功能
提高图像的对比度
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 局部模式 | 局域或全局直方图均衡,勾选则局域直方图均衡,取消勾选则全局直方图均衡 | 勾选 | / |
| 对比度阈值 | 对比度阈值 | 3 | [1,1000] |
1.1.5 通过颜色过滤深度图
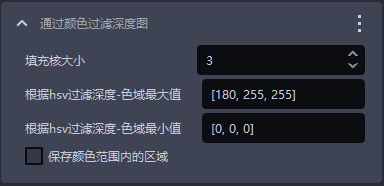
- 功能
根据颜色值过滤深度图
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 填充核大小 | 颜色填充的大小 | 3 | [1,99] |
| 根据hsv过滤深度-色域最大值 | 最大颜色值 | [180,255,255] | [[0,0,0],[255,255,255]] |
| 根据hsv过滤深度-色域最小值 | 最小颜色值 | [0,0,0] | [[0,0,0],[255,255,255]] |
| 保存颜色范围内的区域 | 勾选则保存颜色范围内的区域,不勾选则保存颜色范围外的区域 | / | / |
1.1.6 伽马图片校正
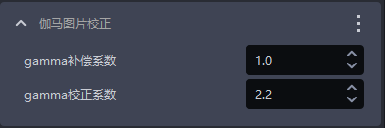
- 功能
gamma校正改变图片亮度
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| gamma补偿系数 | 该值小于1,图片变暗该值大于1,图片变量 | 1 | [0.1,100] |
| gamma校正系数 | 该值小于1,图片变暗,适用于亮度过高的图片该值大于1,图片变亮,适用于亮度过低的图片 | 2.2 | [0.1,100] |
1.1.7 填充深度图空洞

- 功能
对深度图中的空洞区域进行填充,并对填充后的深度图进行平滑处理
- 使用场景
因工件本身结构遮挡、光照不均匀等问题,深度图可能缺失工件的部分区域
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 填充核大小 | 空洞填充的大小 | 3 | [1,99] |
填充核大小只能填入奇数
- 调参
根据检测结果调整,如果填充过度,应调小参数;如果填充不足,应调大参数
- 示例
1.1.8 边缘增强
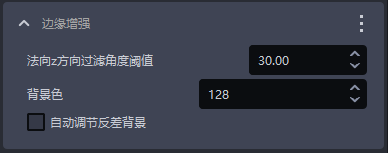
- 功能
把图像中纹理的边缘部分置为背景色或者与背景色相差较大的颜色,以凸显工件的边缘信息
- 使用场景
工件相互遮挡或重叠导致边缘不清晰
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 | 调参建议 |
|---|---|---|---|---|
| 法向z方向过滤阈值 | 深度图每个点对应的法向量与相机坐标系Z轴正方向的角度过滤阈值,若点的法向量与相机坐标系的Z轴正方向的角度大于此阈值,则2D图中该点对应位置的颜色将会被置为背景色或者与背景色相差较大的颜色 | 30 | [0,180] | 对于平整工件表面,该阈值可以小一些,曲面工件根据表面倾斜程度适当增大 |
| 背景色 | 背景色的RGB颜色阈值 | 128 | [0,255] | |
| 自动调节反差背景 | 勾选 自动调节反差背景后,将2D图中角度大于过滤阈值的点的颜色设置为与背景色相差较大的颜色不勾选 自动调节反差背景,将2D图中角度大于过滤阈值的点的颜色设置为背景色对应的颜色 | 不勾选 | / |
- 示例
1.1.9 提取最上层纹理

- 功能
提取最上层或最底层的工件纹理,而把其他区域置为背景色或者与背景颜色相差较大的颜色。
- 使用场景
光照条件不佳、颜色纹理相近、紧密堆叠、交错堆叠或遮挡等因素可能导致模型难以区分上层和下层工件的纹理差异,因此容易误检测。
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 | 单位 | 调参建议 |
|---|---|---|---|---|---|
| 距离阈值(mm) | 点与最上层平面(最底层平面)的距离低于该阈值,则被认为是最上层平面(最底层平面)内的点,应当保留,否则认为是下层(上层)的点,将下层(上层)的点的颜色置为背景色或与背景色相差较大的颜色 | 50 | [0.1, 1000] | mm | 一般调整为工件高度的1/2 |
| 聚类点云数量 | 期望参与聚类的点数量,在ROI 3D区域内采样点云的数量 | 10000 | [1,10000000] | / | 聚类点云数量越多,模型推理速度下降而精度提升;聚类点云数量越少,模型推理速度提升而精度下降 |
| 类别点最小数量 | 用于过滤类别的最小点数 | 1000 | [1, 10000000] | / | / |
| 自动计算反差背景 | 勾选 自动计算反差背景后,将2D图中最上层(最底层)外的其他区域设置为与背景色阈值相差较大的颜色不勾选 自动计算反差背景,将2D图中最上层(最底层)外的其他区域设置为背景色阈值对应的颜色 | 勾选 | / | / | / |
| 背景色阈值 | 背景色RGB颜色阈值 | 128 | [0,255] | / | / |
1.1.10 去除roi3d外的图片背景
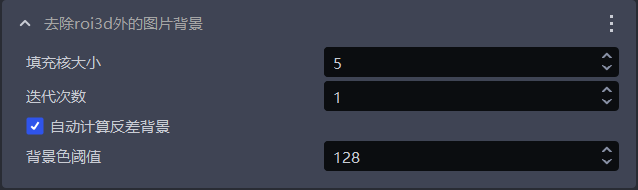
- 功能
去除2D图像中除了ROI3D区域以外的背景
- 使用场景
图像背景噪声较多影响检测结果
- 参数说明
| 参数名 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 填充核大小 | 空洞填充的大小 | 5 | [1,99] |
| 迭代次数 | 图片膨胀的迭代次数 | 1 | [1,99] |
| 自动计算反差背景 | 勾选 自动计算反差背景后,将2D图中roi以外的区域设置为与背景色阈值相差较大的颜色不勾选 自动计算反差背景,将2D图中roi以外的区域设置为背景色阈值对应的颜色 | 勾选 | / |
| 背景色阈值 | 背景色的RGB颜色阈值 | 128 | [0,255] |
填充核大小只能填入奇数
- 调参
如果需要去除图像中更多背景噪声,应当调小填充核大小
- 示例
1.2 实例分割
1.2.1 缩放比例
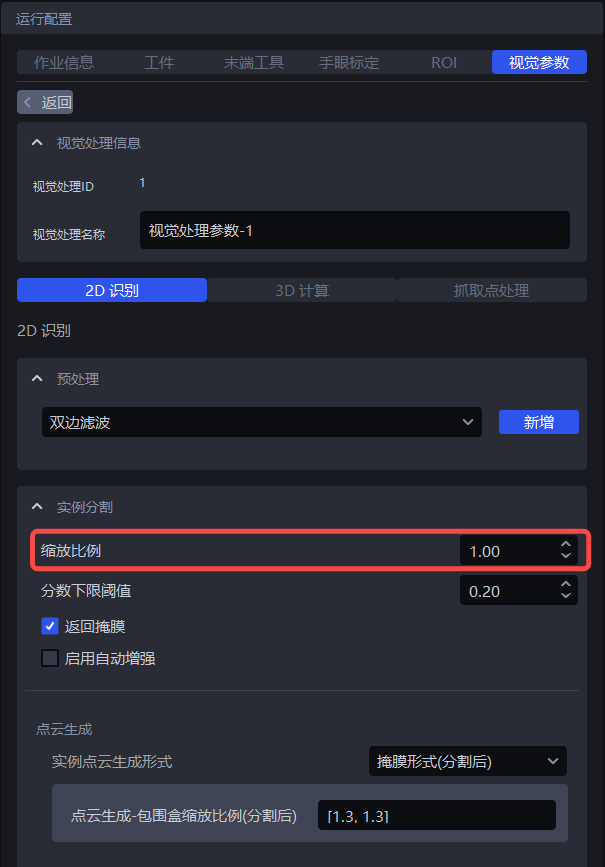
- 功能
通过等比放缩原始图像后再推理以提升2D识别的准确率与召回率。
- 使用场景
检测效果不佳(如未检测到实例、漏识别、包围盒框到多个实例或框不满实例)应调整该函数。
- 参数说明
默认值:1.0
取值范围:[0.01, 3.00]
步长:0.01
调参
- 使用默认值运行,在可视化视窗查看检测结果,若出现未检测到实例、漏识别、包围盒框到多个实例或框不满实例的情况,应调整该函数。
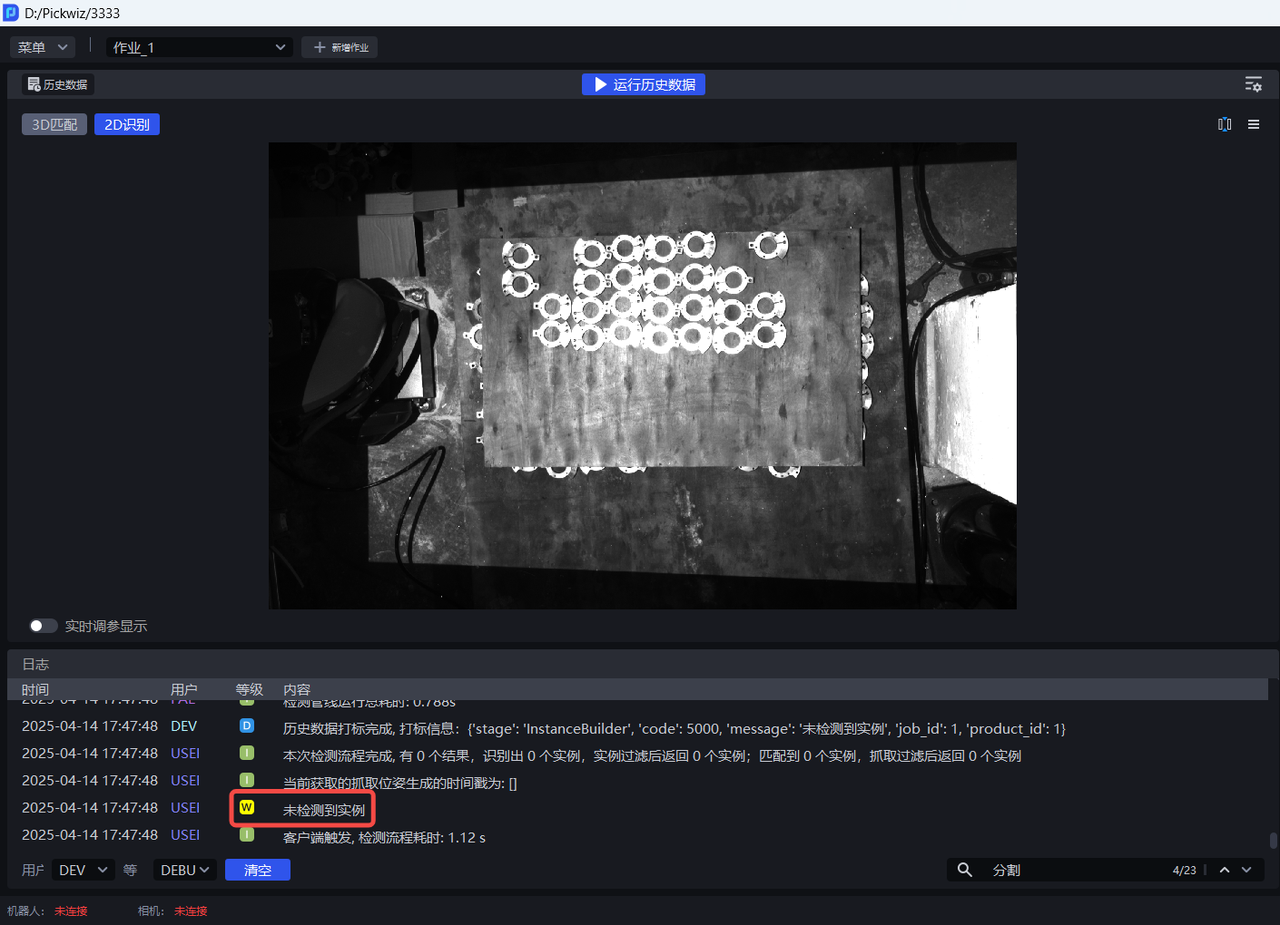
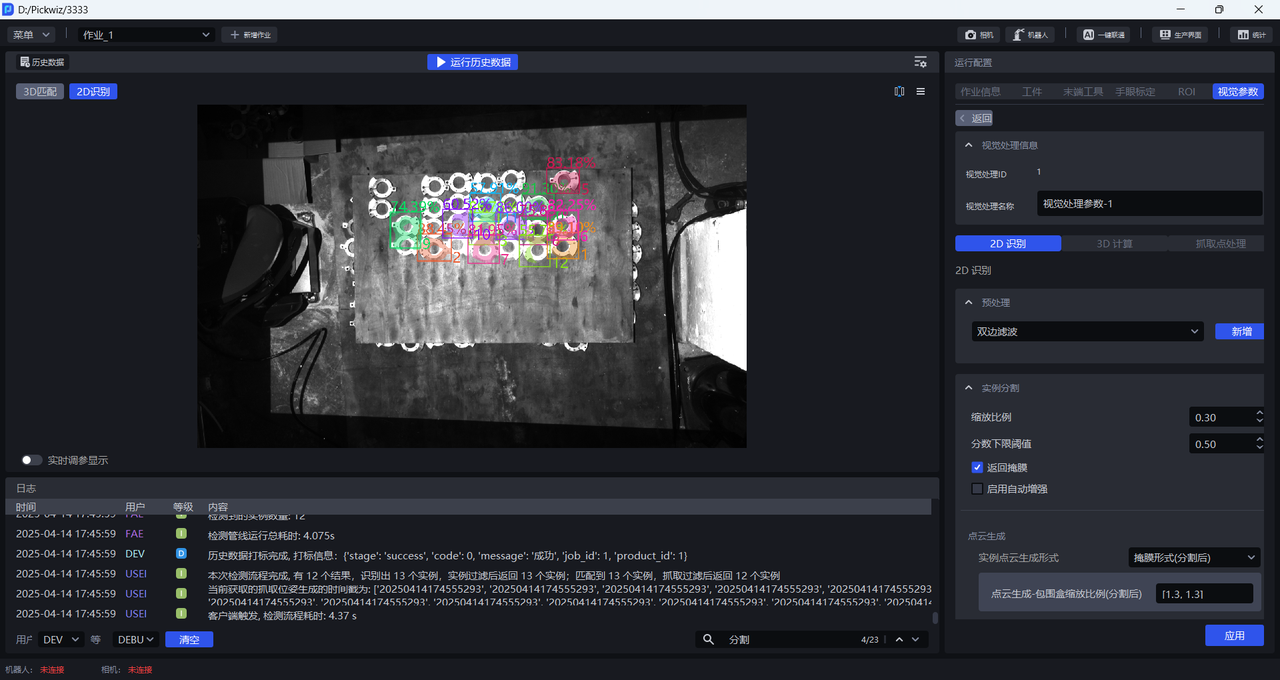
2D识别中实例的百分数为置信度分数,数字为实例ID(实例的识别顺序)。
2D识别中实例上有颜色的阴影是掩膜,包围实例的矩形框是包围盒。
- 尝试不同的缩放比例,观察检测结果的变化,逐步确定缩放比例的范围。如果在某个缩放比例下,检测效果显著提高,则将该缩放比例作为下限;在某个缩放比例下,检测效果显著降低,则将该缩放比例作为上限。
若尝试所有缩放比例都无法获得较好检测结果,可调整ROI区域
如下图所示,缩放比例为0.33时检测效果显著提高,因此可以确定0.33为缩放比例范围的下限
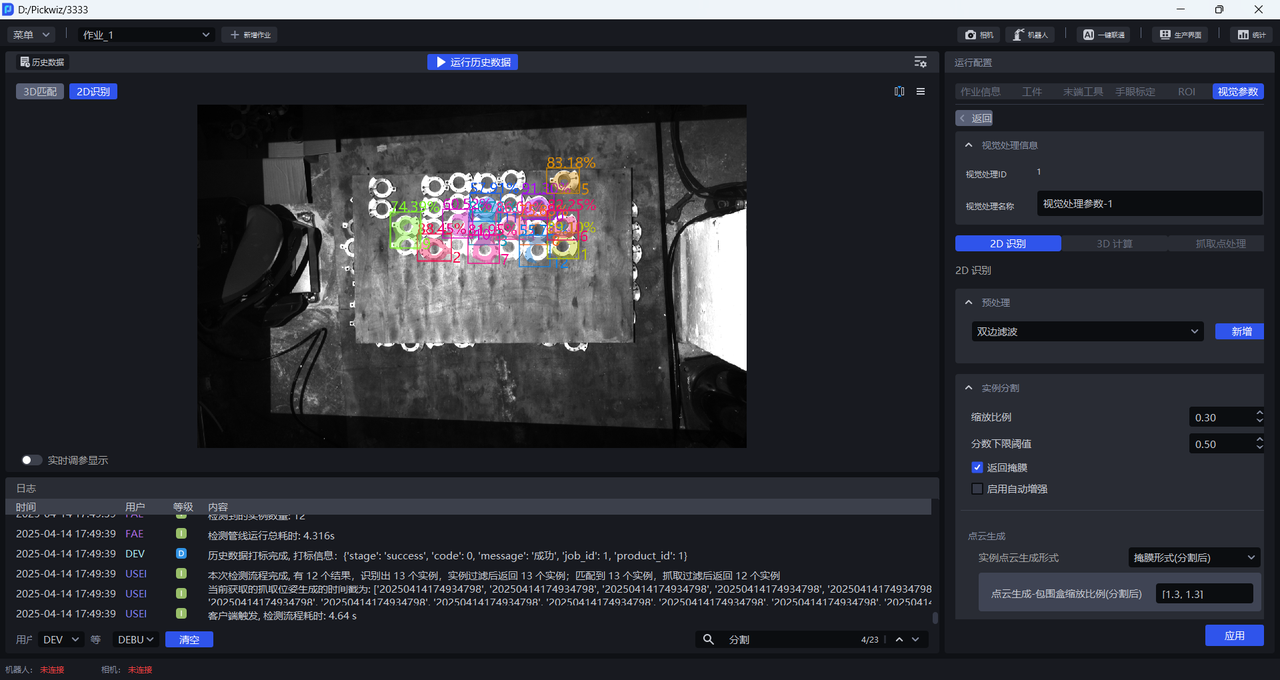
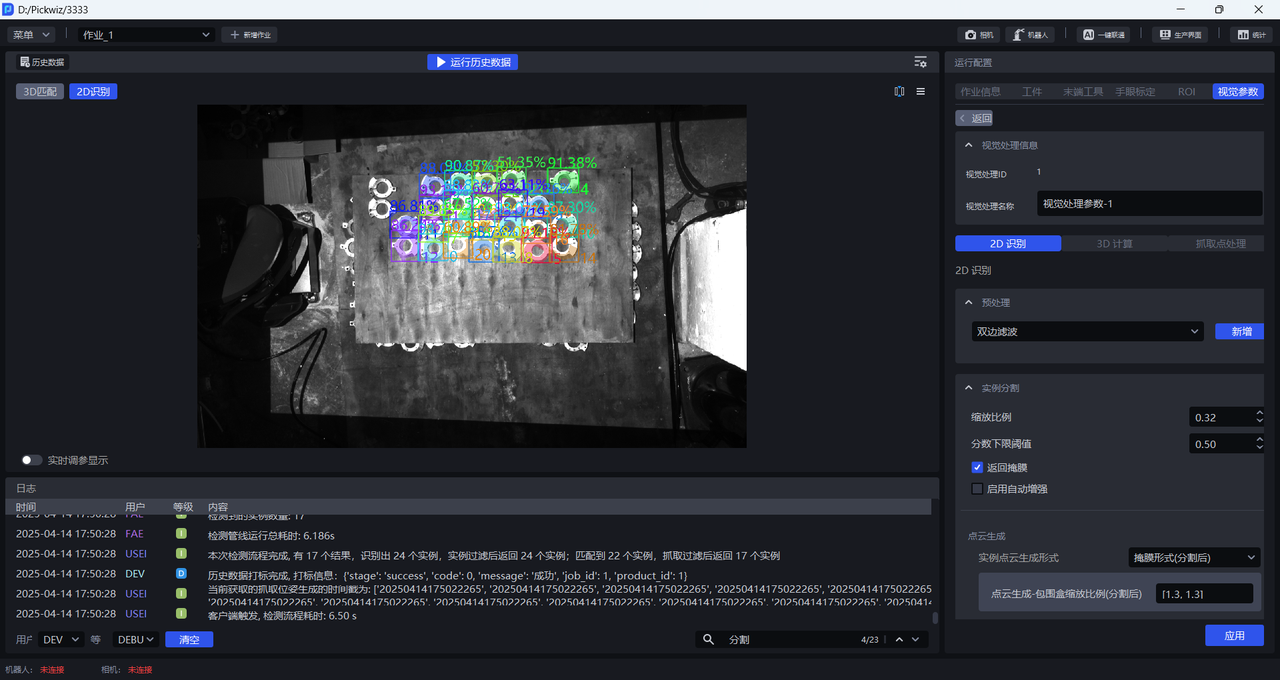
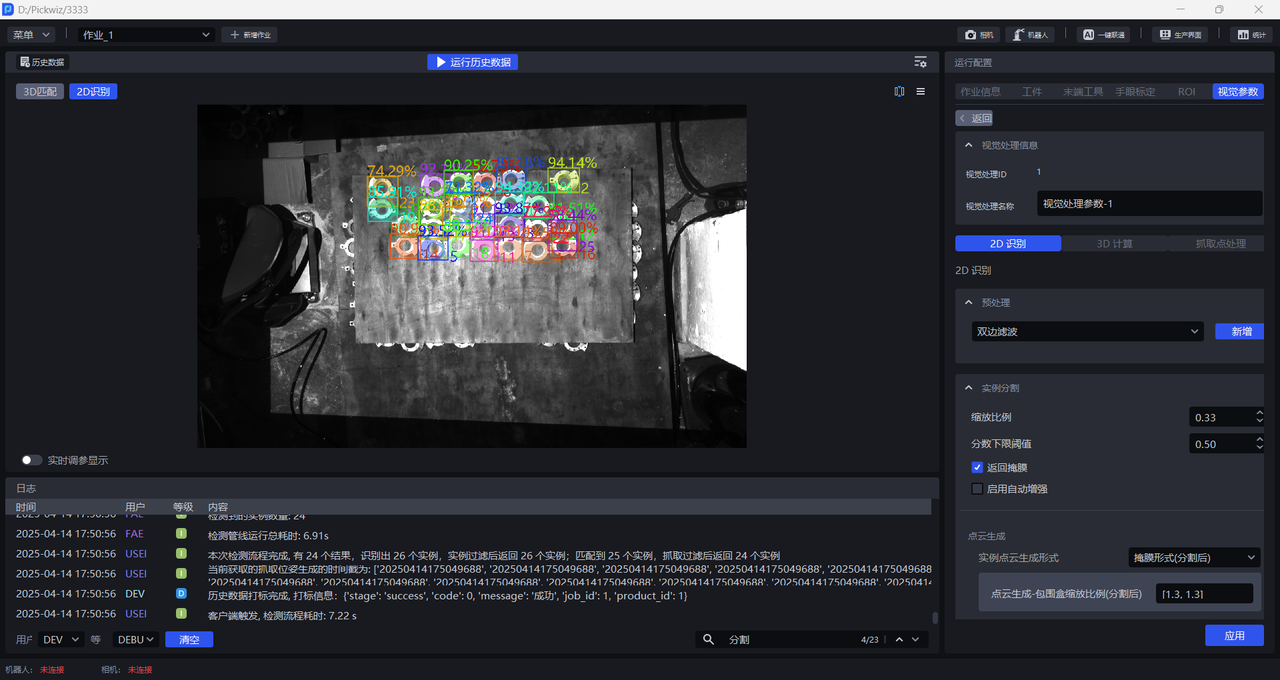
缩放比例为3时检测效果依然较好,因此可以确定3为缩放比例范围的上限
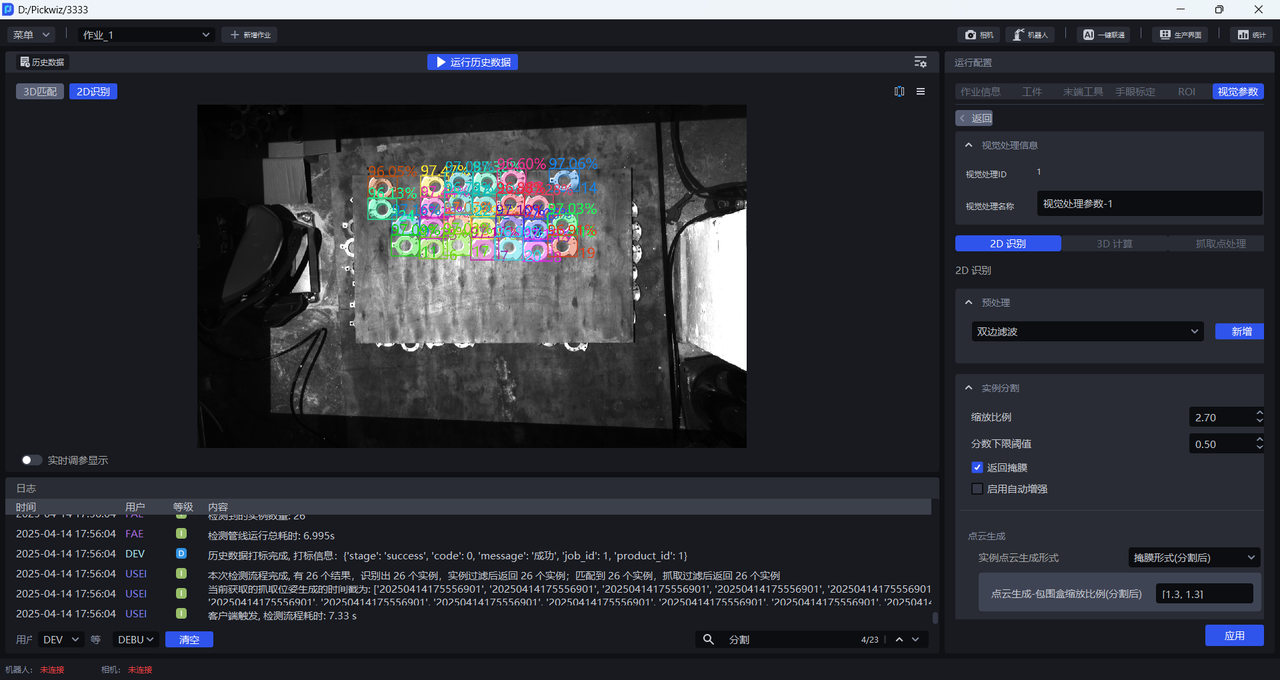
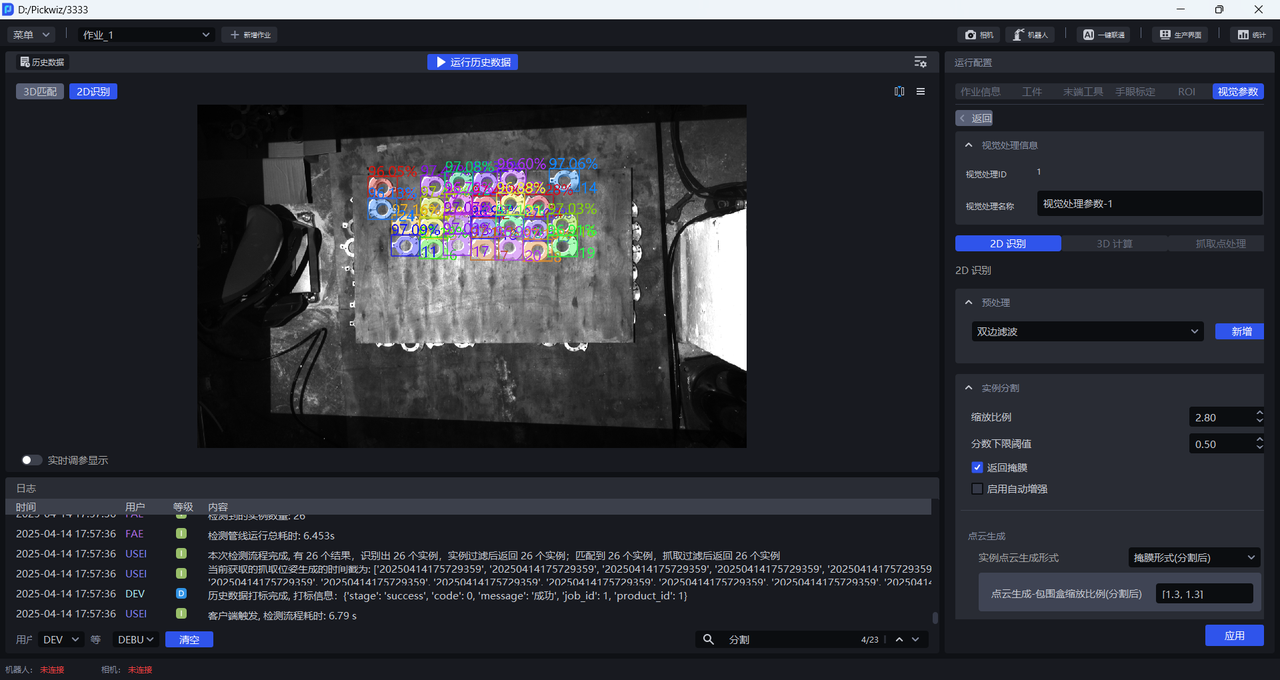
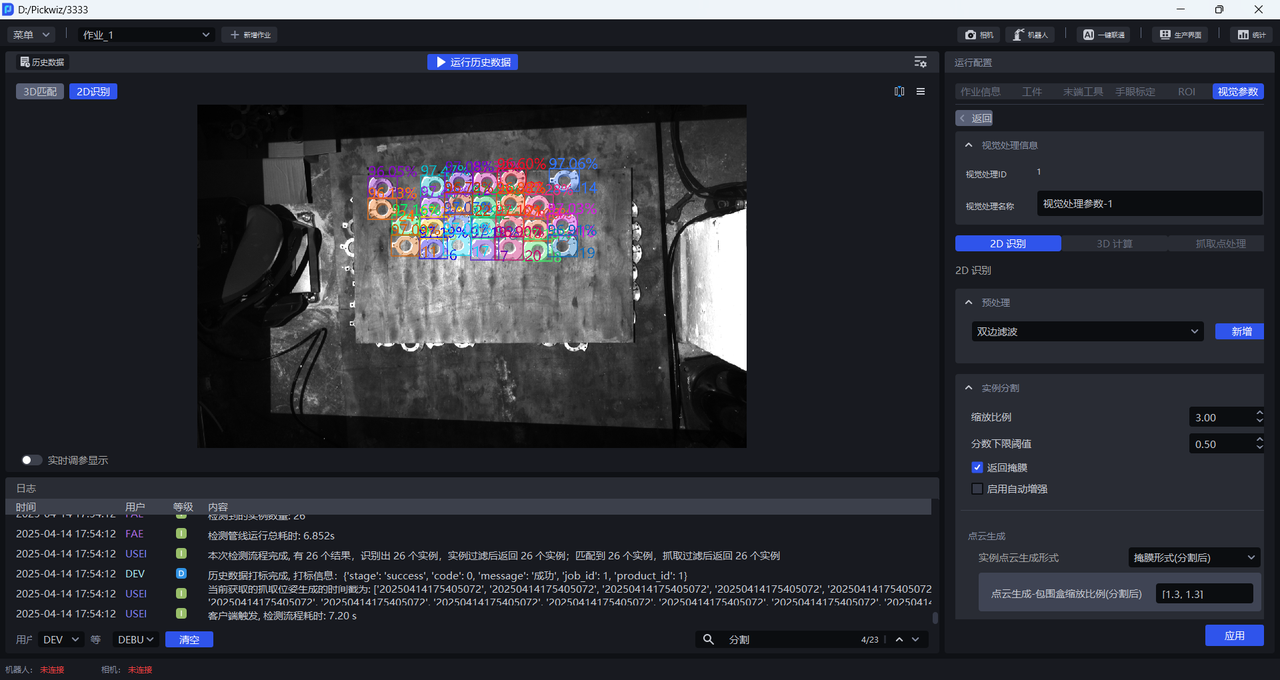
- 如果实际场景对抓取精度要求不高,可以在[0.33,3]区间内选择一个检测效果较好的缩放比例;如果实际场景对抓取精度要求较高,应当进一步细化缩放比例范围,按更小步长来调整,直至找到检测效果最佳的缩放比例。
1.2.2 置信度下限阈值
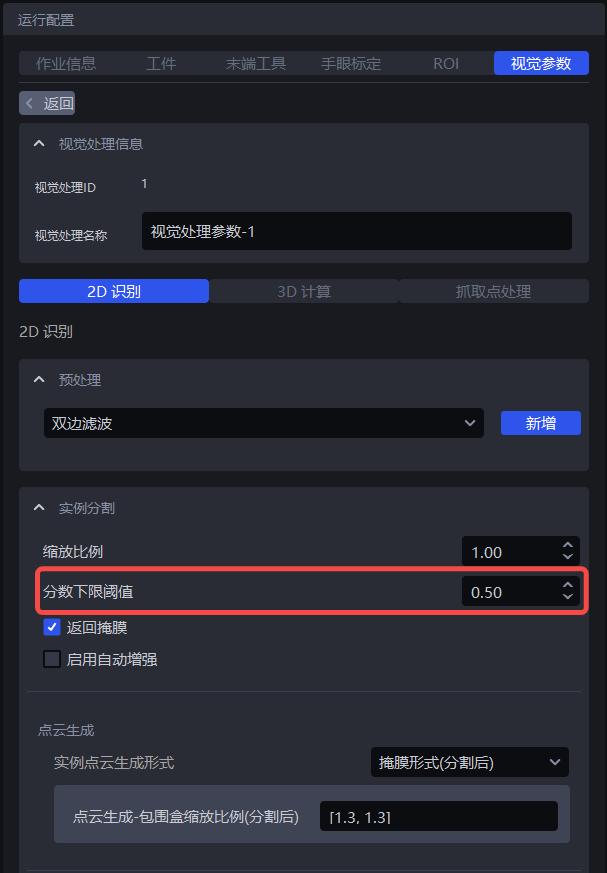
- 功能
仅保留深度学习模型识别结果分数高于置信度下限阈值的识别结果
- 使用场景
检测结果框取的实例不符预期时,可调整该函数
- 参数说明
默认值:0.5
取值范围:[0.01, 1.00]
调参
- 如果模型检测出的实例较少,应当调小该阈值;取值过小,可能会影响图像识别的准确度。
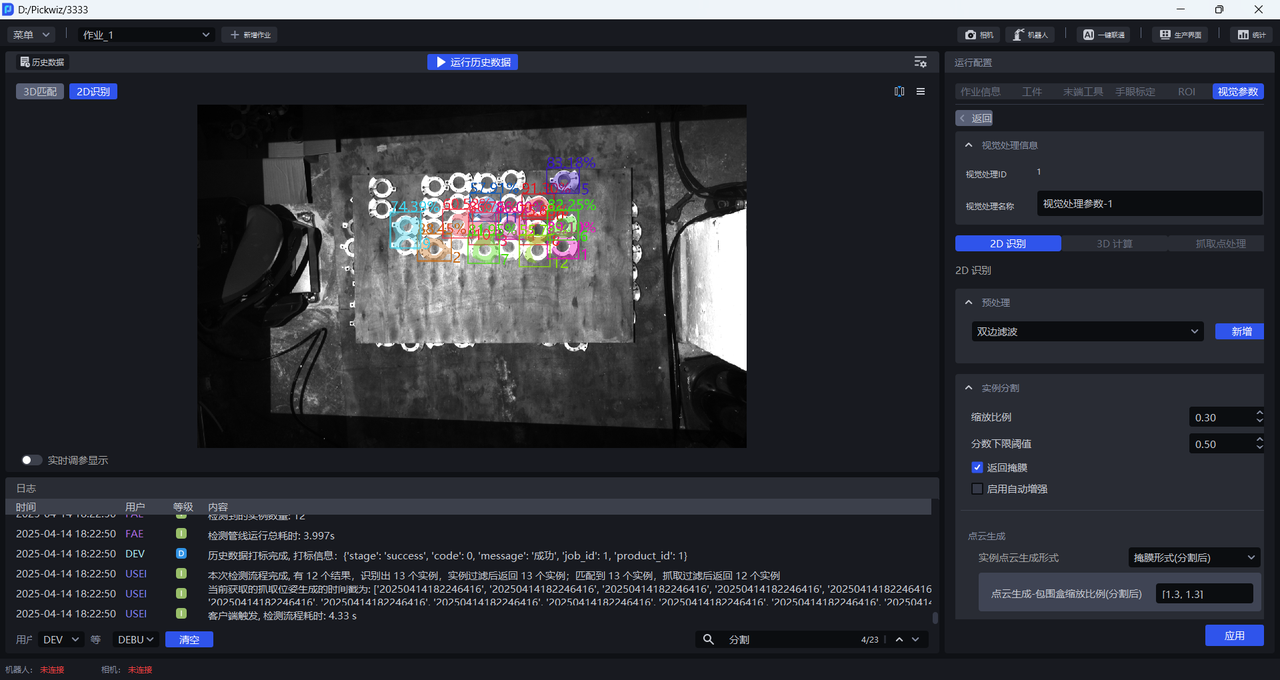
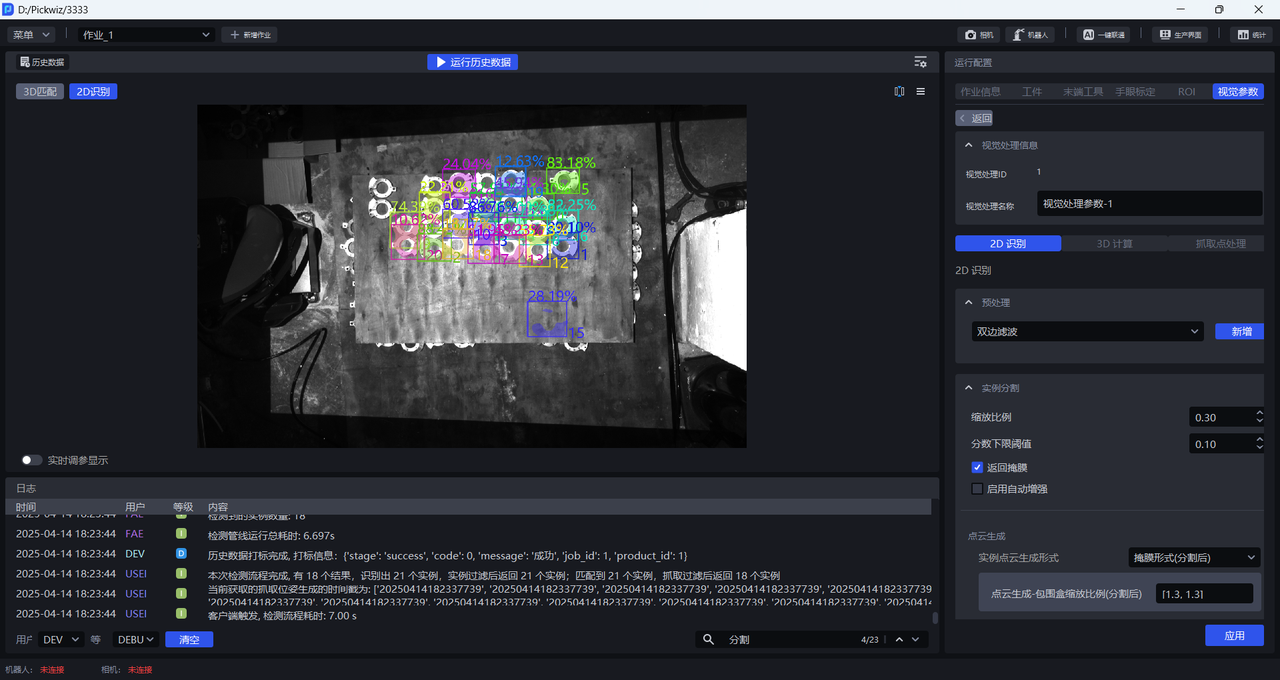
- 若因为置信度下限阈值过小导致检测出错误的实例,而需要去除这些错误的实例,应当调大该阈值;取值过大,可能会导致保留的检测结果为零,没有结果输出。
1.2.3 启用自动增强
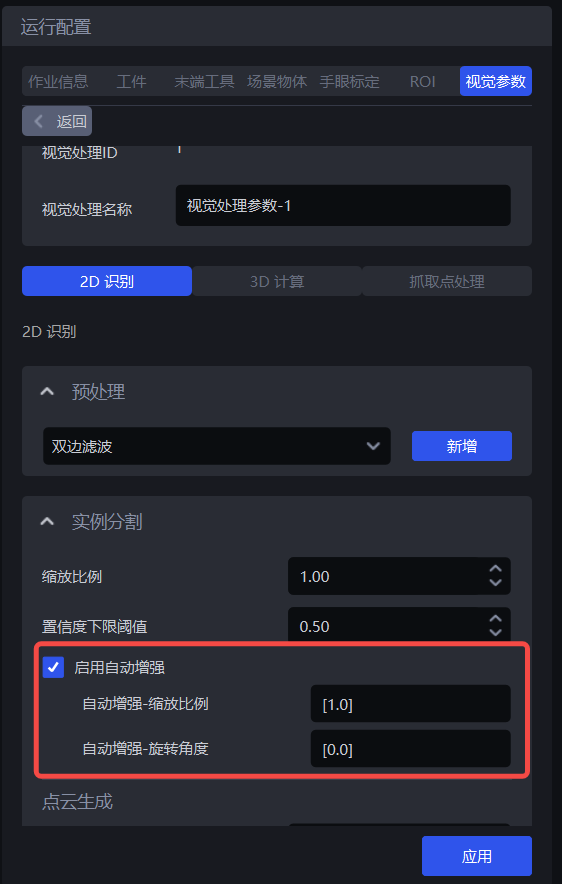
- 功能
将输入的缩放比例和旋转角度中所有的值进行组合后推理,返回组合后大于设定置信度下限阈值的所有结果,可以提升模型推理精度, 但会增加耗时。
- 使用场景
单个缩放比例无法满足实际场景需求导致检测不完整或物体摆放倾斜度较高。
- 示例
如果自动增强-缩放比例设置为 [0.8, 0.9, 1.0] ,自动增强-旋转角度设置为 [0, 90.0] ,那么将缩放比例和旋转角度中的值两两组合,模型内部会自动生成6种图片进行推理,最后将这6种推理结果统一到一起,输出大于置信度下限阈值的结果。
自动增强-缩放比例

- 功能
对原始图像进行多次缩放并进行多次推理,输出综合的推理结果
- 使用场景
单个缩放比例无法满足实际场景需求导致检测不完整
- 参数说明
默认值:[1.0]
取值范围:每个缩放比例的范围为[0.1, 3.0]
可设置多个缩放比例,每个缩放比例之间用英文逗号隔开
- 调参
填入多个 1.2.1 缩放比例 获得的检测效果较好的缩放比例
自动增强-旋转角度

- 功能
对原始图像多次旋转并进行多次推理,输出综合的推理结果
- 使用场景
物体摆放偏离坐标轴较多时使用
- 参数说明
默认值:[0.0]
取值范围:每个旋转角度的取值范围为[0, 360]
可设置多个旋转角度,每个旋转角度之间用英文逗号隔开
- 调参
根据实际场景中的物体角度调整自动增强-旋转角度,可根据麻袋的图案和袋口形状、纸箱的棱边和品牌标志判断倾斜角度
1.3 点云生成
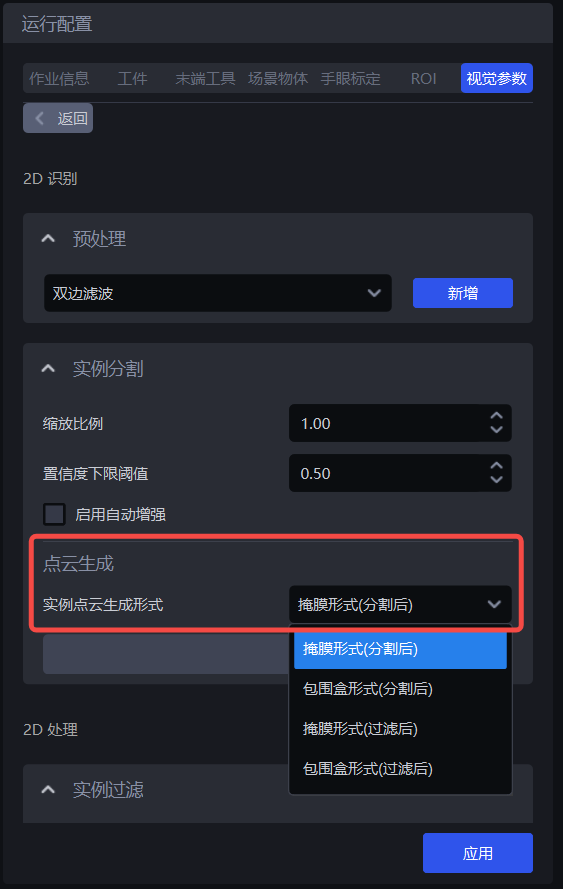
| 实例点云生成形式 | 掩膜形式(分割后) | — | 使用分割后的实例掩膜生成点云 |
| 包围盒形式(分割后) | 包围盒缩放比例(分割后) | 使用分割后的实例包围盒生成点云 | |
| 生成点云是否需要颜色(分割后) | 生成的实例点云是否需要附着颜色 | ||
| 掩膜形式(过滤后) | — | 使用过滤后的实例掩膜生成点云 | |
| 包围盒形式(过滤后) | 包围盒缩放比例(过滤后) | 使用过滤后的实例包围盒生成点云 | |
| 生成点云是否需要颜色(过滤后) | 生成的实例点云是否需要附着颜色 |
如果不需要加速,无需使用实例过滤函数,使用掩膜形式(分割后)或包围盒形式(分割后)生成实例点云,可在 项目存储文件夹\项目名称\data\PickLight\历史数据时间戳\Builder\pose\input文件夹查看生成的实例点云;
如果需要加速,可使用实例过滤函数对实例进行过滤,使用掩膜形式(过滤后)或包围盒形式(过滤后)生成实例点云,可在 项目存储文件夹\项目名称\data\PickLight\历史数据时间戳\Builder\pose\input文件夹查看生成的实例点云
1.4 实例过滤
1.4.1 基于包围盒面积过滤
- 功能介绍
根据检测出实例的包围盒的像素面积来进行过滤。
- 使用场景
适用于实例包围盒面积相差较大的场景,通过设置包围盒面积的上限和下限来过滤图像中的噪声,提升图像识别的准确度,避免噪声给后续处理增加耗时。
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 | 单位 |
|---|---|---|---|---|
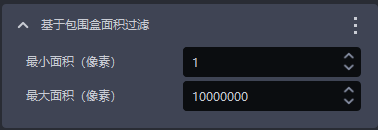
| 最小面积(像素) | 该参数用于设置包围盒的最小过滤面积,包围盒面积低于这个值的实例会被过滤 | 1 | [1, 10000000] | 像素点 |
| 最大面积(像素) | 该参数用于设置包围盒的最大过滤面积,包围盒面积高于这个值的实例会被过滤 | 10000000 | [2, 10000000] | 像素点 |
- 示例
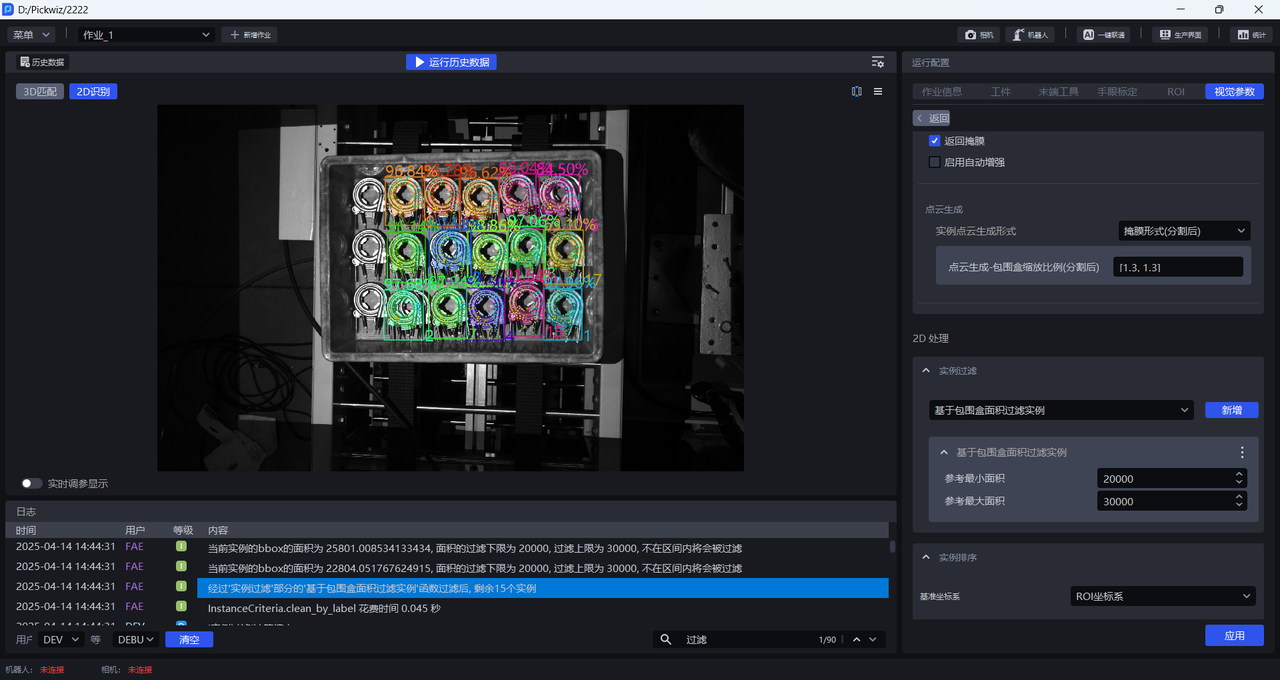
按默认值运行,可在日志中查看每个实例的包围盒面积,如下图所示。
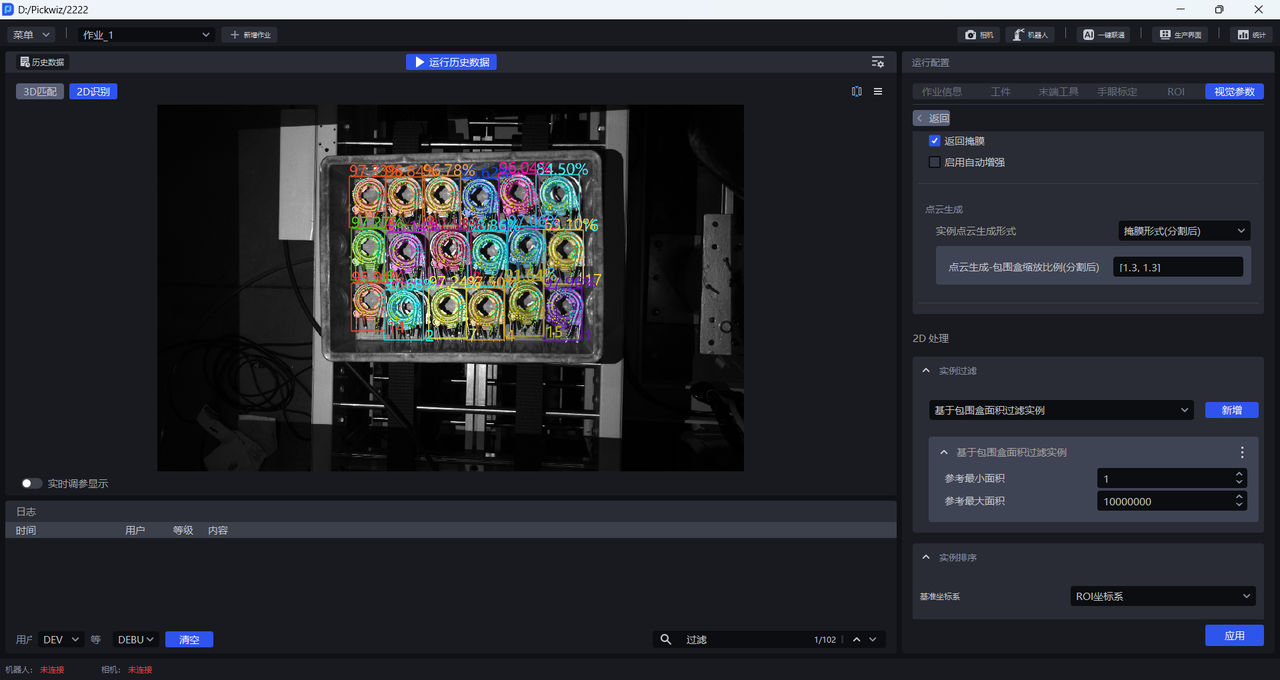
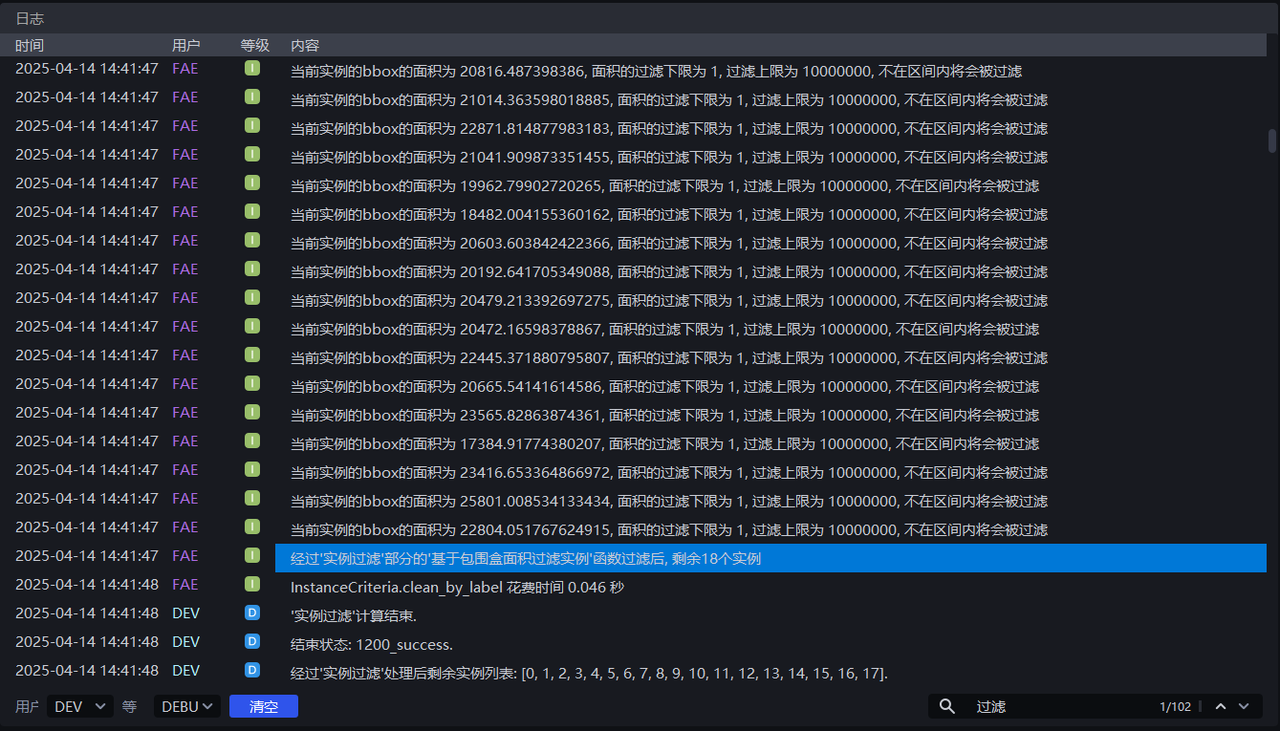
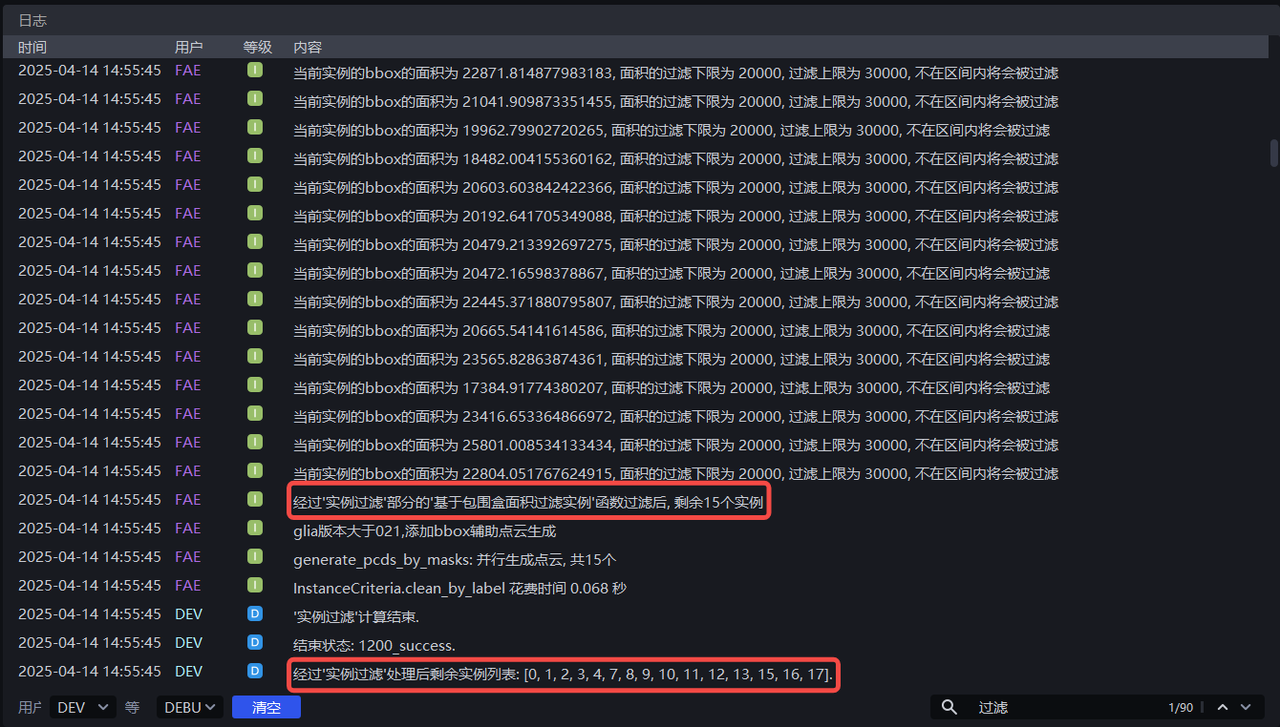
根据每个实例的包围盒面积调整 最小面积 和 最大面积,如将最小面积设置为20000,将最大面积设置为30000,即可将像素面积为小于20000或大于30000的实例过滤掉,可在日志中查看实例过滤过程。
1.4.2 基于包围盒长宽比过滤
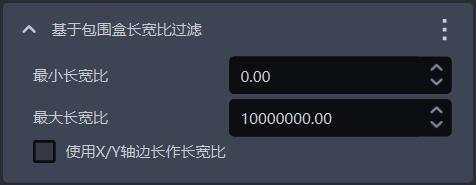
- 功能介绍
包围盒长宽比在指定范围外的实例将被过滤掉
- 使用场景
适用于实例的包围盒长宽比相差较大的场景
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 |
|---|---|---|---|
| 最小长宽比 | 包围盒长宽比的最小值,包围盒长宽比低于该值的实例会被过滤 | 0 | [0, 10000000] |
| 最大长宽比 | 包围盒长宽比的最大值,包围盒长宽比高于该值的实例会被过滤 | 10000000 | [0, 10000000] |
| 使用X/Y轴边长作长宽比 | 默认不勾选,使用包围盒的较长边/较短边的长度比值作为长宽比,适用于包围盒的长短边长度相差大的情况; 勾选后,则使用像素坐标系下包围盒在X轴/Y轴上的边的长度比值作为长宽比,适用于大部分正常实例包围盒的长边/短边比值近似,但部分异常识别的实例包围盒在X轴上的长度/在Y轴上的长度的比值相差较大的情况。 | 不勾选 | / |
1.4.3 基于类别ID过滤实例

- 功能介绍
根据实例类别过滤
- 使用场景
适用于来料有多种类型工件的场景
- 参数说明
| 参数 | 说明 | 默认值 |
|---|---|---|
| 保留的类别ID | 保留类别ID在列表内的实例,类别ID不在列表内的实例将被过滤 | [0] |
- 示例
1.4.4 基于实例点云的边长过滤
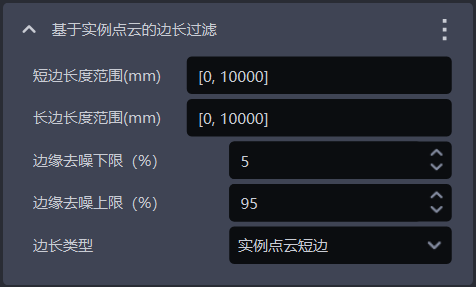
- 功能介绍
根据实例点云的长边和短边过滤
- 使用场景
适用于实例点云在x轴或y轴的距离相差较大的场景,通过设置实例点云的距离范围来过滤图像中的噪声,提升图像识别的准确度,避免噪声给后续处理增加耗时。
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 | 单位 |
|---|---|---|---|---|
| 短边长度范围(mm) | 点云短边的边长范围 | [0, 10000] | [0, 10000] | mm |
| 长边长度范围(mm) | 点云长边的边长范围 | [0, 10000] | [0, 10000] | mm |
| 边缘去噪下限(%) | 提取实例点云中X/Y值(相机坐标系)的百分比下限,去除上下限外的点云,避免噪点影响长度计算 | 5 | [0, 100] | / |
| 边缘去噪上限(%) | 提取实例点云中X/Y值(相机坐标系)的百分比上限,去除上下限外的点云,避免噪点影响长度计算 | 95 | [0, 100] | / |
| 边长类型 | 按实例点云的长边、短边过滤,长边、短边的长度不在范围内的实例将被过滤 | 实例点云短边 | 实例点云短边;实例点云长边;实例点云长边和短边 | / |
- 示例
1.4.5 基于分类器的类别ID过滤
- 功能介绍
基于分类器的类别 ID 过滤实例,不在参考类别内的实例将被过滤。
- 使用场景
在多类工件场景中,视觉模型可能会检测出多种类型的工件,但实际作业可能仅需其中某一种类别的工件,此时就可以使用该函数过滤掉不需要的工件
- 参数说明
默认值为[0],即默认保留类别 ID 为 0 的实例,类别 ID 不在列表内的实例将被过滤。
1.4.6 基于三通道颜色过滤
- 功能介绍
可通过三通道颜色阈值(HSV或者RGB)过滤掉实例。
- 使用场景
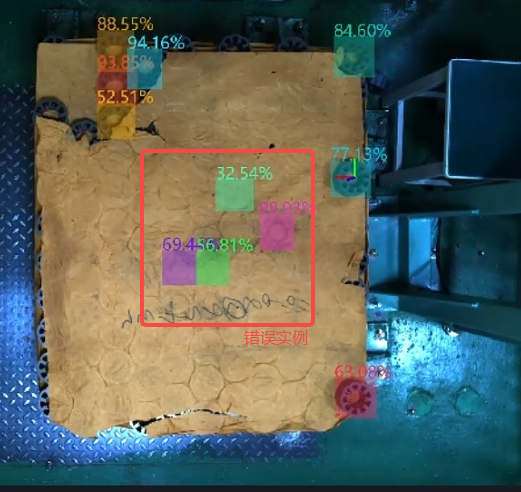
错误实例和正确实例颜色有明显区分的情况。
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 色域最大值 | 最大颜色值 | [180,255,255] | [[0,0,0],[255,255,255]] |
| 色域最小值 | 最小颜色值 | [0,0,0] | [[0,0,0],[255,255,255]] |
| 过滤百分比阈值 | 颜色通过率阈值 | 0.05 | [0,1] |
| 反向过滤 | 勾选则剔除颜色范围外的比例低于阈值的实例,不勾选则剔除实例图像中颜色范围内的比例低于阈值的实例 | 不勾选 | / |
| 颜色模式 | 颜色过滤中选择的颜色空间 | HSV色彩空间 | RGB色彩空间HSV色彩空间 |
- 示例
1.4.7 基于置信度过滤
- 功能介绍
根据实例的置信度分数过滤
- 使用场景
适用于实例的置信度相差较大的场景
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 |
|---|---|---|---|
| 参考置信度度 | 保留置信度大于阈值的实例,过滤置信度小于阈值的实例。 | 0.5 | [0,1] |
| 反转过滤结果 | 反转后,保留可见度置信度小于阈值的实例,过滤置信度大于阈值的实例。 | 不勾选 | / |
- 示例
1.4.8 基于点云数量过滤
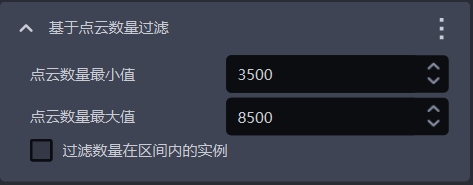
- 功能介绍
根据降采样后的实例点云数量过滤
- 使用场景
实例点云带有较多噪声
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 |
|---|---|---|---|
| 点云数量最小值 | 点云数量的最小值 | 3500 | [1, 10000000] |
| 点云数量最大值 | 点云数量的最大值 | 8500 | [2, 10000000] |
| 过滤数量在区间内的实例 | 勾选则过滤点云数量在最小值和最大值区间内的实例,不勾选则过滤点云数量不在区间内的实例 | 不勾选 | / |
1.4.9 基于掩膜面积过滤
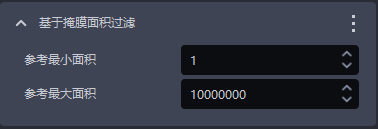
- 功能介绍
根据检测出实例的掩膜像素和(即像素面积)过滤图像掩膜。
- 使用场景
适用于实例掩膜面积相差较大的场景,通过设置掩膜的面积上限和下限来过滤图像掩膜中的噪声,提升图像识别的准确度,避免噪声给后续处理增加耗时。
- 参数设置说明
| 参数名 | 说明 | 默认值 | 参数范围 | 单位 |
|---|---|---|---|---|
| 参考最小面积 | 该参数用于设置掩膜的最小过滤面积,掩膜面积低于这个值的实例会被过滤 | 1 | [1, 10000000] | 像素点 |
| 参考最大面积 | 该参数用于设置掩膜的最大过滤面积,掩膜面积高于这个值的实例会被过滤 | 10000000 | [2, 10000000] | 像素点 |
- 示例
1.4.10 基于可见度过滤
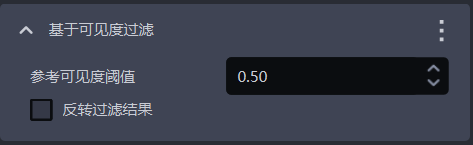
- 功能介绍
根据实例的可见度分数过滤
- 使用场景
适用于实例的可见度相差较大的场景
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 |
|---|---|---|---|
| 参考可见度阈值 | 保留可见度大于阈值的实例,过滤可见度小于阈值的实例。可见度用于判断图像中的实例可见的程度,工件被遮挡越多,可见度越低。 | 0.5 | [0,1] |
| 反转过滤结果 | 反转后,保留可见度小于阈值的实例,过滤可见度大于阈值的实例。 | 不勾选 | / |
1.4.11 过滤包围盒重叠的实例
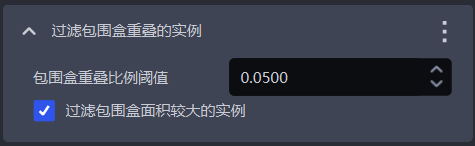
- 功能介绍
过滤包围盒交叉重叠的实例
- 使用场景
适用于实例的包围盒相互交叉的场景
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 |
|---|---|---|---|
| 包围盒重叠比例阈值 | 包围盒交叉的面积与实例包围盒的面积的占比阈值 | 0.05 | [0, 1] |
| 过滤包围盒面积较大的实例 | 勾选则过滤两个包围盒交叉的实例中面积较大的实例,不勾选则过滤两个包围盒交叉的实例中面积较小的实例 | 勾选 | / |
- 示例
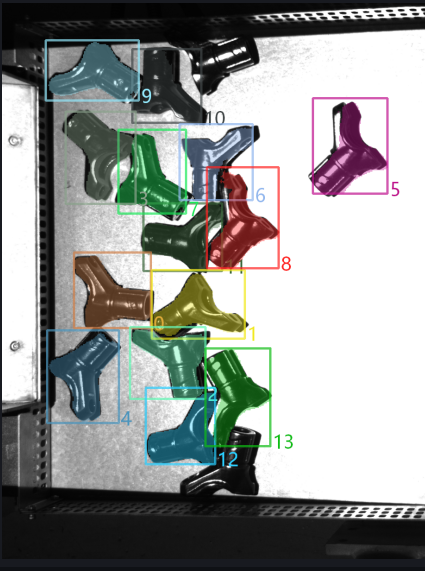
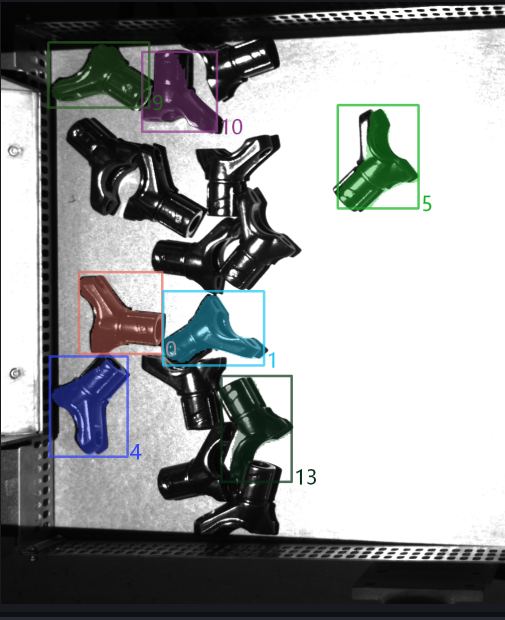
新增 过滤被包围实例,以默认值运行,在日志中查看实例包围盒交叉的情况,实例过滤后剩余2个实例
由日志可知,12个实例因为包围盒交叉被过滤掉,剩余2个包围盒没有交叉的实例

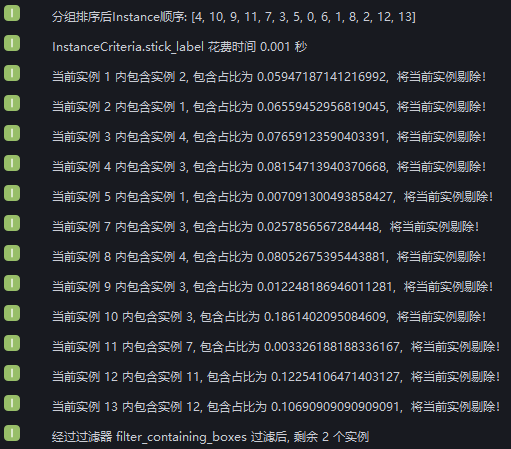
将 包围盒重叠比例阈值 设置为0.1,勾选 是否过滤较大的实例,在日志中查看实例例过滤过程,9个实例因为包围盒交叉面积与实例包围盒面积的占比大于0.1被过滤掉,3个实例因为包围盒交叉面积与实例包围盒面积的占比小于0.1被保留,2个实例包围盒没有交叉。

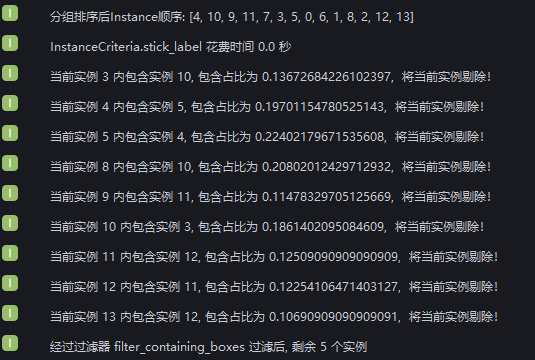
将 包围盒重叠比例阈值 设置为0.1,取消勾选 是否过滤较大的实例,在日志中查看实例例过滤过程,9个实例的包围盒交叉面积与实例包围盒面积的占比大于0.1,但其中2个实例因为包围盒面积小于与其交叉的实例被保留,因此7个实例被过滤,3个实例因为包围盒交叉面积与实例包围盒面积的占比小于0.1被保留,2个实例包围盒没有交叉。
1.4.12 【大师】基于掩膜/掩膜外接多边形面积比,过滤掩膜凹凸的实例
- 功能介绍
计算掩膜/掩膜外接多边形的面积比值,若小于设置的阈值则会过滤掉实例
- 使用场景
适用于工件掩膜存在锯齿/凹凸的情况。
- 参数说明
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 面积比阈值 | 掩膜/凸包面积比阈值,若小于设置的阈值则会过滤掉实例。 | 0.1 | [0,1] |
1.4.13 【大师】基于点云平均距离过滤

- 功能介绍
基于点云中点到拟合平面的距离的平均值进行过滤,剔除不平整的实例点云
- 使用场景
适用于平面型工件点云弯曲的场景
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 | 单位 |
|---|---|---|---|---|
| 平面分割距离阈值(mm) | 在弯曲的实例点云中提取一个平面,与平面的距离小于该阈值的点视为该平面的点 | 10 | [-1000, 1000] | mm |
| 平均距离阈值(mm) | 实例点云中的点到提取平面的距离的平均值 | 20 | [-1000, 1000] | mm |
| 剔除平均距离小于阈值的实例 | 勾选则过滤点到提取平面的平均距离小于平均距离阈值的实例,不勾选则过滤点到提取平面的平均距离大于平均距离阈值的实例 | 不勾选 | / | / |
1.4.14 【大师】基于掩膜/包围盒面积比,过滤被遮挡的实例
- 功能介绍
计算掩膜/包围盒面积比值,比值不在最大最小范围内的实例将被过滤
- 使用场景
用于过滤被遮挡工件的实例
- 参数说明
,相反,代表可能被遮挡。
| 参数 | 说明 | 默认值 | 取值范围 |
|---|---|---|---|
| 最小面积比 | 掩膜/包围盒面积比例范围下限,比值越小,说明实例被遮挡程度越高 | 0.1 | [0,1] |
| 最大面积比 | 掩膜/包围盒面积比例范围上限,比值越接近1,说明实例被遮挡程度低 | 1.0 | [0,1] |
1.4.15 【大师】判断最上层实例是否全量检出
- 功能介绍
防呆机制之一,判断最上层的实例是否全部被检出,若存在没有被检出的最上层实例则会报错并结束工作流
- 使用场景
适用于拍一次抓多次或者必须要按顺序进行抓取的场景,防止因实例检出不完整造成漏抓影响后续作业
- 参数说明
| 参数 | 说明 | 默认值 | 参数范围 | 单位 | 调参 |
|---|---|---|---|---|---|
| 距离阈值 | 用于判断最上层的工件,点与工件点云最高点的距离小于距离阈值,则认为这个点是最上层点云,否则认为这个点不是最上层点云。 | 5 | [0.1, 1000] | mm | 应当小于工件的高度 |
1.5 实例排序
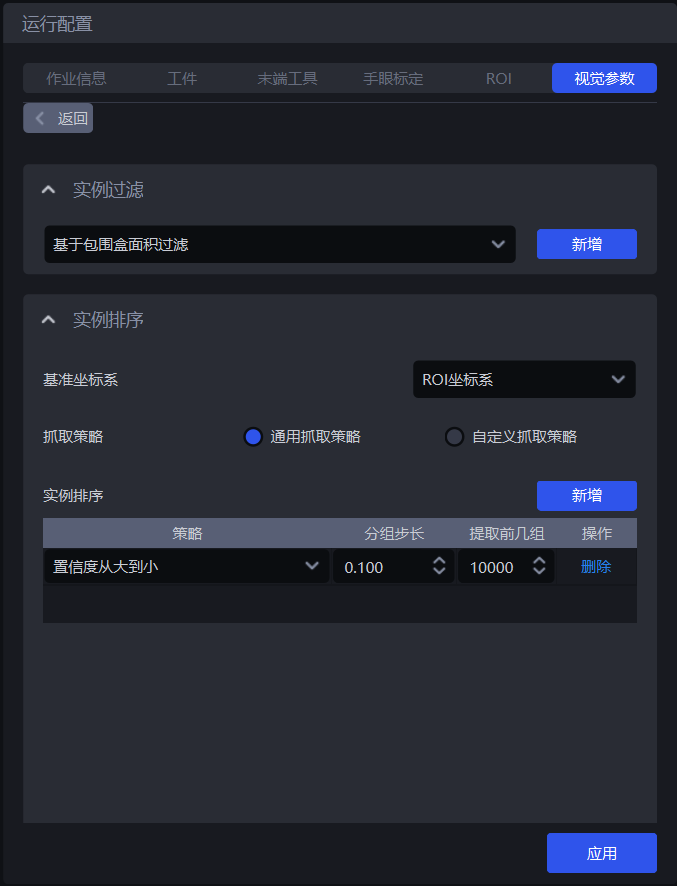
- 功能介绍
根据选择的策略对实例进行分组、排序、提取
- 使用场景
拆垛、无序抓取、有序上下料场景通用
如果不需要排序,可以不配置具体的策略。
1.5.1 基准坐标系
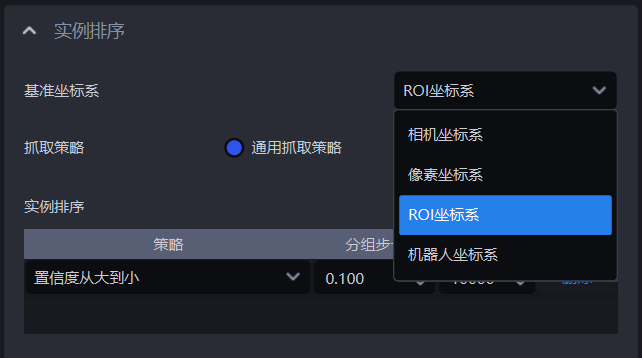
- 功能介绍
为所有实例设定一个统一的坐标系,进行实例的分组排序
- 使用场景
拆垛场景、无序抓取场景、有序上下料场景通用
使用坐标相关的策略应当先设置基准坐标系
- 参数说明
| 参数 | 说明 | 图示 |
|---|---|---|
| 相机坐标系 | 坐标系原点在物体上方,Z轴正方向朝下;XYZ取值是物体中心点在该坐标系下的值 |  |
| ROI坐标系 | 坐标系原点大致在垛中心,Z轴正方向朝上;XYZ取值是物体中心点在该坐标系下的值 | 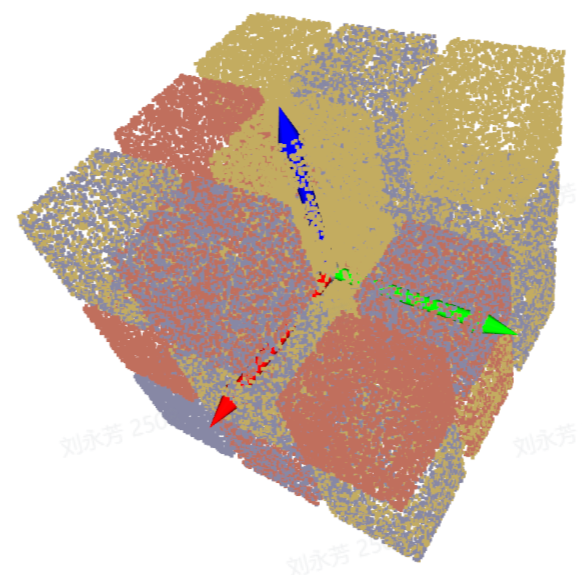 |
| 机械臂坐标系 | 坐标系原点在机械臂自身,Z轴正方向一般朝上;XYZ取值是物体中心点在该坐标系下的值 |  |
| 像素坐标系 | 坐标系原点在RGB图的左顶点,是二维平面坐标系;X、Y取值是bbox识别框的x值、bbox识别框的y值,Z是0 |  |
1.5.2 通用抓取策略
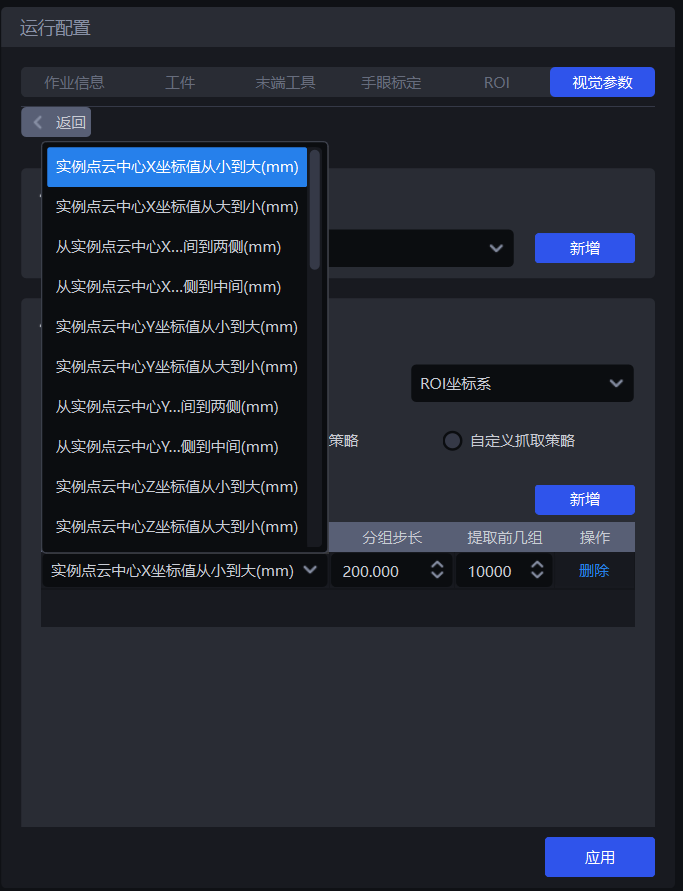
- 参数说明
| 参数 | 说明 | 默认值 |
|---|---|---|
| 策略 | 选择依据哪个值进行分组排序以及如何排序,包括实例点云中心XYZ坐标值、包围盒长宽比、实例点云中心距离ROI中心等可叠加多条,按顺序依次执行 | 实例点云中心X坐标值从小到大(mm) |
| 分组步长 | 依据选择的策略、按照步长将实例划分为若干组,分组步长即两组实例之间的间隔如策略选择”实例点云中心Z坐标值从大到小(mm)“,则将所有实例点云中心的Z坐标从大到小排序,然后按照步长把Z坐标分组,相应的实例也划分为若干组 | / |
| 提取前几组 | 分组排序之后,需要保留多少组实例 | 10000 |
| 策略名* | 说明 | 分组步长 | 提取前几组 | |
|---|---|---|---|---|
| 默认值 | 取值范围 | 默认值 | ||
| 实例点云中心XYZ坐标值从大到小/从小到大(mm) | 使用每个实例的点云中心的XYZ坐标值来进行分组排序 使用该策略进行排序前应当先设置基准坐标系 | 200.000 | (0, 10000000] | 10000 |
| 从实例点云中心XY坐标轴向的中间到两侧/从实例点云中心XY坐标轴的两侧到中间(mm) | 使用每个实例的点云中心的 XY 坐标值,按照 “中间到两侧” 或 “两侧到中间” 的方向进行分组排序 使用该策略进行排序前应当先设置基准坐标系 | 200.000 | (0, 10000000] | 10000 |
| 包围盒中心XY坐标值从大到小/从小到大(mm) | 使用像素坐标系下,每个实例的包围盒中心点的XY 坐标值进行分组排序 | 200.000 | (0, 10000000] | 10000 |
| 包围盒长宽比从大到小/从小到大 | 使用包围盒的长边/宽边的比值进行分组排序 | 1 | (0, 10000] | 10000 |
| 从包围盒中心XY坐标轴向的中间到两侧/两侧到中间(mm) | 使用包围盒的中心点的XY坐标值,按照 “中间到两侧” 或 “两侧到中间” 的方向进行分组排序 | 200.000 | (0, 10000000] | 10000 |
| 工件类型ID从大到小/从小到大 | 使用工件类型的ID进行分组排序,适用于多类工件场景 | 1 | [1, 10000] | 10000 |
| 局部特征ID从大到小/从小到大 | 使用局部特征的ID进行分组排序 | 1 | [1, 10000] | 10000 |
| 置信度从大到小/从小到大 | 使用每个实例的置信度进行分组排序 | 1 | (0, 1] | 10000 |
| 可见度从小到大/从大到小 | 使用每个实例的可见度进行分组排序 | 1 | (0, 0.1] | 10000 |
| 掩膜面积从大到小/从小到大 | 使用每个实例的掩膜面积进行分组排序 | 10000 | [1, 10000000] | 10000 |
| 实例点云中心距离ROI中心近到远/远到近(mm) | 使用每个实例的点云中心与ROI坐标系的中心的距离进行分组排序 | 200.000 | (0, 10000000] | 10000 |
| 实例点云中心距离机器人坐标原点近到远/远到近(mm) | 使用每个实例的点云中心与机器人坐标系的原点的距离进行分组排序 | 200.000 | (0, 10000000] | 10000 |
- 示例
1.5.3 自定义抓取策略
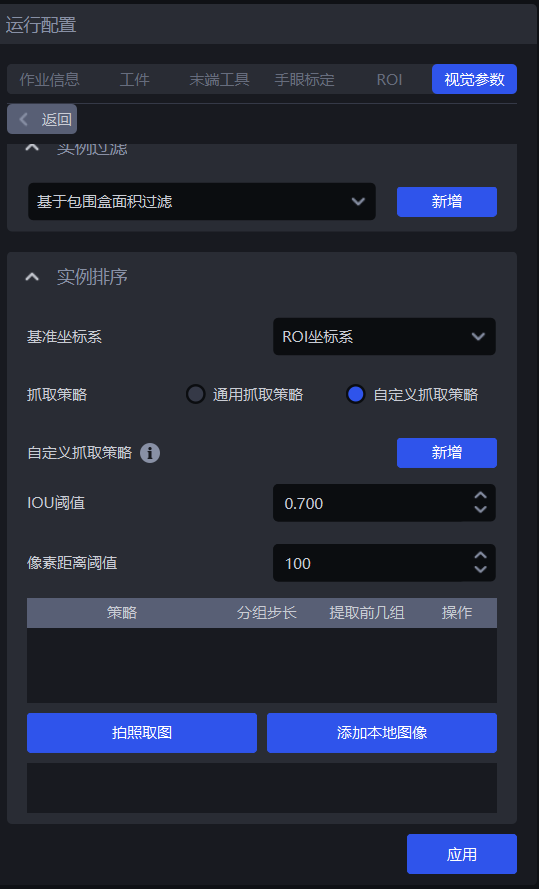
(1)功能说明
将抓取策略切换为自定义抓取策略,点击 新增 可增加一条自定义抓取策略。
自定义每个工件按照什么顺序抓取,使用通用抓取策略很难实现抓取或者因为点云噪点等问题很难调到合适的参数,可以考虑使用自定义抓取策略
自定义抓取策略适用于拆垛场景、有序上下料场景,无序抓取场景不适用,因为自定义抓取策略的工件必须是有序的(即工件的顺序固定)
自定义抓取策略只能和单个通用抓取策略组合使用,且策略只能选择Z坐标从小到大
(2)参数说明
| 参数 | 说明 | 默认值 | 取值范围 | 调参 |
|---|---|---|---|---|
| IOU阈值 | 表示标注的bbox框和检测出来的bbox框的重叠度阈值,通过重叠度来确定当前工件实例排序时应该选择哪一张图片上的排序方式。 | 0.7 | [0,1] | 阈值越大,匹配越严格,抗干扰性会越差,微小的形状或位置变化都可能导致匹配失败,可能匹配到错误的自定义策略,按错误的顺序进行排序 |
| 像素距离阈值 | 表示可以匹配上的bbox框和检测出来的bbox框在尺寸上的差异性。 | 100 | [0,1000] | 阈值越小,匹配越严格,抗干扰性也会更好。如果不同层之间的工件摆放比较相似,也可能误匹配自定义策略,导致排序顺序错误。 |
(3)选择基准坐标系
使用自定义抓取策略,只能选择相机坐标系或像素坐标系
如果有多层工件,则选择相机坐标系;如果只有一层工件,则选择像素坐标系
(4)策略、分组步长、提取前几组
| 参数 | 说明 | 默认值 |
|---|---|---|
| 策略 | 只能选择实例点云中心Z坐标值从大到小/从小到大(mm) | / |
| 分组步长 | 依据Z坐标从小到大策略,将实例的Z坐标从小到大排序,按照步长将实例划分为若干组 | 10000 |
| 提取前几组 | 分组排序之后,需要保留多少组实例 | 10000 |
(5)拍照取图/添加本地图像
点击拍照取图从当前连接的相机获取图像,或点击添加本地图像从本地导入图像,有多少层或有多少种工件的不同摆放形式,就需要拍照取图或添加本地图像得到多少张图片,如果每一层相同,只需要一张即可。鼠标右键点击图像可删除。
在获取的图像上长按拖动鼠标左键标注bbox框,DELETE键可逐步删除标注的bbox框。
2. 3D计算
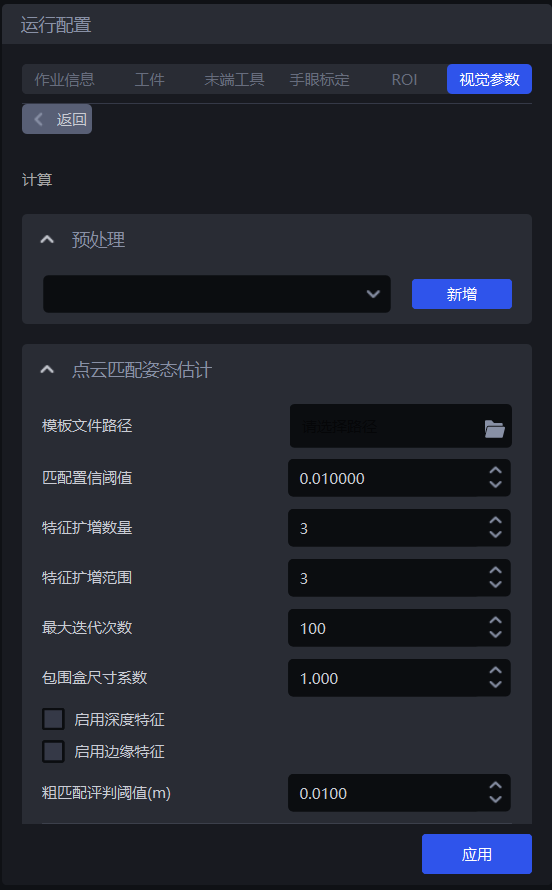
2.1 预处理
3D计算的预处理是在对实例进行姿态估计、生成抓取点之前对3D点云进行处理,面型工件有序上下料(并行化)场景无需对3D点云进行处理。
2.2 点云匹配姿态估计
2.2.1 模板文件路径

- 功能
上传点云模板与场景的实例点云进行匹配
- 使用场景
面型工件有序上下料(并行化)场景
- 调参说明
该点云模板需使用模板生成脚本制作,制作方法如下:
- 复制场景的2D图、深度图、点云图
(1)选择要复制的历史数据的时间戳
从PickLight历史数据文件夹中选取一个时间戳文件夹(如 /home/xxx/PickLight/20240718201333036),复制其完整路径备用。
(2)下载模板生成脚本
注意:
模板生成脚本需要下载与软件版本相对应的版本,否则版本不兼容会导致点云模板生成失败。
模板生成脚本的下载目录不能有中文或特殊字符,建议存储在默认的下载目录C:
\Users\dex\Downloads
PickWiz 版本 > =1.8.0 模版生成脚本:点击查看完整代码
模板生成脚本
import argparse
import math
import os
import shutil
from copy import deepcopy
import cv2
import json
import numpy as np
import open3d as o3d
import torch
from kornia.filters import sobel as kornia_sobel
# from PickLight.Utils.Convertor import generate_mask_from_points
# from PickLight.Utils.Utility import FileOperation
try:
import glia
if not glia.__version__ >= "0.2.4":
raise RuntimeError("请将 glia 版本升级到 0.2.4 或者更高. 目前版本为 {}").format(glia.__version__)
from glia.dl.models.superglue import SuperGlueMatcher
except Exception:
raise ImportError(f"Glia 版本过低, 请先升级Glia, 当前版本为 {glia.__version__}.\n")
from typing import Optional
def generate_mask_from_points(
points: np.array,
K: np.array,
h: int,
w: int,
image: Optional[None] = None,
kernel_size: Optional[int] = 5,
iterations: Optional[int] = 1,
auto_scale=4,
) -> np.array:
"""Given camera intrinsic parameters K, image size hxw, and marked points,
this function is to project marked points to image plane and generate mask.
Args:
points (np.array): marked points with size n x 3.
K (np.array): camera intrinsic parameters, 3 x 3.
h (int): image height.
w (int): image width.
image (Optional[cv2.mat], optional): If provided, this function will additionally
provide mask on this image. Defaults to None.
kernel_size (Optional[int], optional): To avoid uncontinuous mask,
use morphology kernel. This parameter defines kernel size. Defaults to 5.
Returns:
np.array: mask given by points, on h x w canvas.
"""
K_ = deepcopy(K)
K_[:2, :] = K_[:2, :] / auto_scale
rvec, tvec = cv2.Rodrigues(np.eye(3))[0], np.zeros((3, 1))
image_points, _ = cv2.projectPoints(
points,
rvec,
tvec,
K_,
np.zeros(
5,
),
)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (kernel_size, kernel_size))
pixel_indices = image_points.squeeze(1).astype(np.int32)
bool_w = np.logical_and(pixel_indices[:, 0] > 0, pixel_indices[:, 0] < int(w / auto_scale))
bool_h = np.logical_and(pixel_indices[:, 1] > 0, pixel_indices[:, 1] < int(h / auto_scale))
valid_pixel_indices = pixel_indices[np.logical_and(bool_w, bool_h), :]
mask = np.zeros((int(h / auto_scale), int(w / auto_scale), 1))
mask[valid_pixel_indices[:, 1], valid_pixel_indices[:, 0], ...] = 1
dilated_mask = cv2.dilate(mask, kernel, iterations)
dilated_mask = cv2.resize(dilated_mask, (w, h), interpolation=cv2.INTER_NEAREST)
if image is None:
return dilated_mask
else:
return dilated_mask, np.multiply(image, np.expand_dims(dilated_mask, -1))
def file_transfer(args):
input_dir = args.data_dir
output_dir = args.output_dir
os.makedirs(output_dir, exist_ok=True)
# RGB+D
try:
for root, dirs, files in os.walk(input_dir):
target_path = os.path.join(root, 'Builder', 'foreground', 'input')
if os.path.exists(target_path):
for file in os.listdir(target_path):
if file.endswith('.png') or file.endswith('.tiff'):
full_file_path = os.path.join(target_path, file)
shutil.copy(full_file_path, output_dir)
print(f'Copied: {file}')
except Exception as e:
raise ValueError(f"检查{input_dir}路径下是否存在Builder/foreground/input文件夹, {e}")
# PCD
try:
for root, dirs, files in os.walk(input_dir):
target_path = os.path.join(root, 'Builder', 'foreground', 'input')
if os.path.exists(target_path):
# 遍历目标路径下的所有文件
for file in os.listdir(target_path):
if file.endswith('.ply'):
full_file_path = os.path.join(target_path, file)
shutil.copy(full_file_path, output_dir)
print(f'Copied: {file}')
except Exception as e:
raise ValueError(f"检查{input_dir}路径下是否存在Builder/foreground/output文件夹, {e}")
# json
try:
for root, dirs, files in os.walk(input_dir):
target_path = os.path.join(root, 'Builder', 'foreground', 'input')
if os.path.exists(target_path):
# 遍历目标路径下的所有文件
for file in os.listdir(target_path):
if file.endswith('.json'):
full_file_path = os.path.join(target_path, file)
shutil.copy(full_file_path, output_dir)
print(f'Copied: {file}')
except Exception as e:
raise ValueError(f"检查{input_dir}路径下是否存在ResourceManager文件夹, {e}")
def search_depth_values(indices, depth_mask, search_radius=3):
"""
在附近搜索一个非零的深度值并填充到深度掩码中
参数:
- indices: 关键点的索引数组,形状为 (N, 2)
- depth_mask: 初始深度掩码,形状为 (H, W)
- search_radius: 搜索半径,默认为 3
返回:
- depth_values: 每个关键点搜索到的深度值
"""
depth_values = np.full(indices.shape[0], -1, dtype=np.float32) # 初始化为 -1 表示未找到非零深度值
for idx, (x, y) in enumerate(indices):
if depth_mask[y, x] == 0:
xmin, xmax = max(0, x - search_radius), min(depth_mask.shape[0], x + search_radius + 1)
ymin, ymax = max(0, y - search_radius), min(depth_mask.shape[1], y + search_radius + 1)
search_area = depth_mask[ymin:ymax, xmin:xmax]
non_zero = search_area[search_area != 0]
if non_zero.size > 0:
depth_values[idx] = non_zero[0]
else:
depth_values[idx] = depth_mask[y, x]
return depth_values
def rotate_pcd(pcd, angle, original_center=None):
# 计算原始中心
if original_center is None:
original_center = pcd.get_center()
# print("原始中心坐标:", np.round(original_center, 3))
# 去中心化(平移至原点)
t_1 = np.array([
[1, 0, 0, -original_center[0]],
[0, 1, 0, -original_center[1]],
[0, 0, 1, -original_center[2]],
[0, 0, 0, 1]
])
# 绕Z轴旋转
theta = np.radians(angle)
cos_theta = np.cos(theta)
sin_theta = np.sin(theta)
t_2 = np.array([
[cos_theta, -sin_theta, 0, 0],
[sin_theta, cos_theta, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]
])
# 返回原中心
t_3 = np.array([
[1, 0, 0, original_center[0]],
[0, 1, 0, original_center[1]],
[0, 0, 1, original_center[2]],
[0, 0, 0, 1]
])
transform_all = np.dot(t_3, np.dot(t_2, t_1))
# print(transform_all)
pcd_final = deepcopy(pcd).transform(transform_all)
# print("最终中心:", np.round(pcd_final.get_center(), 3))
return pcd_final, transform_all
def project_pcd_to_rgb(input_dir, output_dir, angle, auto_scale, mask_kernel_size, edge_kernel_size, index = 1, use_edge = False):
os.makedirs(output_dir, exist_ok=True)
cam_k_path = os.path.join(input_dir, "model_info_0.json")
cam_k = json.load(open(cam_k_path))
cam_k = cam_k["camera_param"]
cam_k = np.asarray(cam_k).reshape(3, 3).astype(np.float32)
pcd_path = os.path.join(input_dir, "model_0.ply")
pcd = o3d.io.read_point_cloud(pcd_path)
temp_img_path = os.path.join(input_dir, "temp_0.png")
temp_img = cv2.imread(temp_img_path)
project_img = np.zeros(temp_img.shape, dtype=np.uint8)
project_depth = np.zeros(temp_img.shape[:2], dtype=np.float32)
aabb = pcd.get_axis_aligned_bounding_box()
aabb_center = (aabb.get_min_bound() + aabb.get_max_bound()) / 2
pcd_transformed, transform_all = rotate_pcd(pcd, angle, aabb_center)
o3d.io.write_point_cloud(os.path.join(output_dir, f"model_{index}.ply"), pcd_transformed)
f_json_data = open(os.path.join(output_dir, f"model_info_{index}.json"), "w+")
json_saved_data = {}
json_saved_data["camera_param"] = cam_k.tolist()
json_saved_data["transform"] = transform_all.tolist()
json_saved_data["angle"] = angle
json_saved_data["use_edge"] = use_edge
json_saved_data["mask_kernel_size"] = mask_kernel_size
json_saved_data["edge_kernel_size"] = edge_kernel_size
json.dump(json_saved_data, f_json_data, indent=4)
f_json_data.close()
rvec = np.array([0.0, 0.0, 0.0]) # 旋转向量
tvec = np.array([0.0, 0.0, 0.0]) # 平移向量
distortion_zeros = np.zeros((5, 1), dtype=np.float32)
pcd_np = np.array(pcd_transformed.points)
points_2d, _ = cv2.projectPoints(pcd_np, rvec, tvec, cam_k, distortion_zeros)
points_2d = points_2d.squeeze(1).reshape(-1, 2)
color_bgr = np.asarray(pcd_transformed.colors)[:,::-1]*255
for i, pt in enumerate(points_2d):
project_img[round(pt[1]), round(pt[0]), :] = color_bgr[i]
project_depth[round(pt[1]), round(pt[0])] = pcd_np[i][2]
mask = np.any(project_img != 0, axis=2)
# 阈值处理分离黑点
project_img = cv2.cvtColor(project_img, cv2.COLOR_BGR2GRAY)
if use_edge:
project_img[mask] = 255
project_img = cv2.morphologyEx(project_img, cv2.MORPH_CLOSE, np.ones((mask_kernel_size, mask_kernel_size), np.uint8))
project_img = cv2.cvtColor(project_img, cv2.COLOR_GRAY2BGR)
cv2.imwrite(os.path.join(output_dir, f"depth_model_{index}.tiff"), project_depth)
cv2.imwrite(os.path.join(output_dir, f"temp_{index}.png"), project_img)
concat_img = cv2.hconcat([project_img, temp_img])
cv2.imwrite(os.path.join(output_dir, f"project_img_concat_{index}.jpg"), concat_img)
# 输出 keypoints.ply
device = 'cuda' if torch.cuda.is_available() else 'cpu'
matching = SuperGlueMatcher().eval().to(device)
matching.set_edge_mode(use_edge)
matching.set_edge_kernel_size(edge_kernel_size)
matching.register(project_img, resolution=(project_img.shape[0], project_img.shape[1]))
keypoints_model_2d = matching.temp_data['keypoints0'][0].cpu().numpy().astype(np.int32)
Keypoint_3D_model = np.zeros((len(keypoints_model_2d), 3), dtype=np.float32)
depth_values = search_depth_values(keypoints_model_2d, project_depth, 5)
# 在文件顶部添加HSV颜色转换函数
def get_rainbow_color(index, total_points):
# 彩虹色谱:Hue 从 0 到 255,S=255, V=255
hsv = np.array([[[int(255 * index / total_points), 255, 255]]], dtype=np.uint8)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)[0][0]
return tuple(map(int, bgr))
temp_vis = deepcopy(project_img)
for i in range(len(keypoints_model_2d)):
x, y = keypoints_model_2d[i]
z = depth_values[i]
if z == -1:
Keypoint_3D_model[i] = [0, 0, 0]
continue
Keypoint_3D_model[i] = np.linalg.inv(cam_k) @ (np.array([x, y, 1]) * z)
# 获取彩虹颜色并绘制
color = get_rainbow_color(i, len(keypoints_model_2d))
center = (int(round(x)), int(round(y)))
cv2.circle(temp_vis, center, radius=1, color=color, thickness=-1)
cv2.imwrite(os.path.join(output_dir, f"temp_vis_{index}.jpg"), temp_vis)
rotated_model_kpts = o3d.geometry.PointCloud()
rotated_model_kpts.points = o3d.utility.Vector3dVector(Keypoint_3D_model)
rotated_model_kpts.colors = o3d.utility.Vector3dVector([[0, 1, 0] for _ in range(Keypoint_3D_model.shape[0])])
o3d.io.write_point_cloud(os.path.join(output_dir, f"keypoints_{index}.ply"), rotated_model_kpts)
torch.cuda.empty_cache()
def generate_superglue_template(args):
data_dir = args.data_dir
auto_scale = args.auto_scale
mask_kernel_size = args.mask_kernel_size
edge_kernel_size = args.edge_kernel_size
ply_path = None
pcd = None
for f in os.listdir(data_dir):
f_path = os.path.join(data_dir, f)
if f.endswith('.ply'):
ply_path = f_path
pcd = o3d.io.read_point_cloud(ply_path)
if f.endswith('.png') or f.endswith('.jpg') or f.endswith('.bmp'):
rgb = cv2.imread(f_path)
h, w = rgb.shape[0], rgb.shape[1]
if f.endswith('.tiff'):
depth = cv2.imread(f_path, -1)
if f.endswith('.json'):
import json
resource_manager = json.load(open(f_path))
cam_k = resource_manager["camera_param"]
cam_k = np.asarray(cam_k).reshape(3, 3).astype(np.float32)
if ply_path is None:
raise ValueError(f"错误! 未在 {data_dir} 路径下找到 点云 文件, 支持后缀为 ply.\n")
if pcd is None:
raise ValueError(f"错误! {ply_path} 路径的点云文件读取失败.\n")
try:
rgb
except NameError:
raise ValueError(f"错误! 未能在 {data_dir} 路径下正确读取 彩色图像 文件, 支持后缀为 png/jpg/bmp.\n")
try:
depth
except NameError:
raise ValueError(f"错误! 未能在 {data_dir} 路径下正确读取 深度图像 文件, 支持后缀为 tiff.\n")
try:
cam_k
except NameError:
raise ValueError(f"错误! 未在 {data_dir} 路径下找到 配置参数 文件, 支持后缀为 json.\n")
mask = generate_mask_from_points(np.array(pcd.points), cam_k, h, w, kernel_size=mask_kernel_size, auto_scale=auto_scale)
# mask 做闭运算,先膨胀后腐蚀
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, np.ones((mask_kernel_size, mask_kernel_size), np.uint8))
if rgb.shape[-1] == 3:
rgb = cv2.cvtColor(rgb, cv2.COLOR_BGR2GRAY)
rgb_mask = deepcopy(rgb)
rgb_mask[mask == 0] = 0
if args.use_edge:
rgb_mask[mask == 0] = 0
rgb_mask[mask != 0] = 255
depth_mask = deepcopy(depth)
# 求rgb_mask中的非零点的AABB,并对rgb_mask进行裁剪
expand_pixels = 10
coords = cv2.findNonZero(mask)
if coords is None or len(coords) == 0:
raise ValueError("mask 中没有非零点,无法进行裁剪")
# 获取初始边界框
x_bbox, y_bbox, w_bbox, h_bbox = cv2.boundingRect(coords)
# 计算扩展后的边界框,确保不超出图像范围
x_expanded = max(0, x_bbox - expand_pixels)
y_expanded = max(0, y_bbox - expand_pixels)
w_expanded = min(w - x_expanded, w_bbox + 2 * expand_pixels)
h_expanded = min(h - y_expanded, h_bbox + 2 * expand_pixels)
# 裁剪图像
rgb_mask = rgb_mask[y_expanded : y_expanded + h_expanded, x_expanded : x_expanded + w_expanded]
depth_mask = depth_mask[y_expanded : y_expanded + h_expanded, x_expanded : x_expanded + w_expanded]
diameter = math.ceil(np.sqrt(w_expanded*w_expanded + h_expanded*h_expanded))
x_pad = (diameter - w_expanded)//2
y_pad = (diameter - h_expanded)//2
rgb_mask_paded = np.zeros([diameter, diameter], dtype=np.uint8)
depth_mask_paded = np.zeros([diameter, diameter], dtype=np.float32)
rgb_mask_paded[y_pad:y_pad + h_expanded, x_pad:x_pad + w_expanded] = rgb_mask
depth_mask_paded[y_pad:y_pad + h_expanded, x_pad:x_pad + w_expanded] = depth_mask
rgb_mask = deepcopy(rgb_mask_paded)
depth_mask = deepcopy(depth_mask_paded)
# 更新相机内参矩阵
cam_k[0, 2] = cam_k[0, 2] - x_expanded + x_pad # 调整cx (主点x坐标),主点的x方向移动了 x_expanded,所以减去
cam_k[1, 2] = cam_k[1, 2] - y_expanded + y_pad # 调整cy (主点y坐标),主点的y方向移动了 y_expanded,所以减去
index = 0
# superglue prompt
use_depth = args.use_depth
use_edge = args.use_edge
superglue_path = os.path.join(data_dir, "superglue")
os.makedirs(superglue_path, exist_ok=True)
# 输出 model.ply
o3d.io.write_point_cloud(f"{superglue_path}/model_{index}.ply", pcd)
# 注册模版输出 temp.png keypoints.ply
temp = deepcopy(rgb_mask)
if use_depth:
temp = deepcopy(depth_mask)
temp = cv2.normalize(temp, None, 0, 255, cv2.NORM_MINMAX).astype(np.uint8)
cv2.imwrite(f"{superglue_path}/depth_mask_uint8_{index}.png", temp)
cv2.imwrite(f"{superglue_path}/depth_model_{index}.tiff", depth_mask)
cv2.imwrite(f"{superglue_path}/temp_{index}.png", temp)
# 输出 keypoints.ply
device = 'cuda' if torch.cuda.is_available() else 'cpu'
matching = SuperGlueMatcher().eval().to(device)
if use_edge:
matching.set_edge_mode(True)
matching.set_edge_kernel_size(edge_kernel_size)
matching.register(temp, resolution=(temp.shape[0], temp.shape[1]))
keypoints_model_2d = matching.temp_data['keypoints0'][0].cpu().numpy().astype(np.int32)
Keypoint_3D_model = np.zeros((len(keypoints_model_2d), 3), dtype=np.float32)
print(len(keypoints_model_2d))
depth_values = search_depth_values(keypoints_model_2d, depth_mask, 5)
temp_vis = deepcopy(rgb_mask)
temp_vis = cv2.cvtColor(temp_vis, cv2.COLOR_GRAY2BGR)
# 在文件顶部添加HSV颜色转换函数
def get_rainbow_color(index, total_points):
# 彩虹色谱:Hue 从 0 到 255,S=255, V=255
hsv = np.array([[[int(255 * index / total_points), 255, 255]]], dtype=np.uint8)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)[0][0]
return tuple(map(int, bgr))
for i in range(len(keypoints_model_2d)):
x, y = keypoints_model_2d[i]
z = depth_values[i]
if z == -1:
Keypoint_3D_model[i] = [0, 0, 0]
continue
Keypoint_3D_model[i] = np.linalg.inv(cam_k) @ (np.array([x, y, 1]) * z)
# 获取彩虹颜色并绘制
color = get_rainbow_color(i, len(keypoints_model_2d))
center = (int(round(x)), int(round(y)))
cv2.circle(temp_vis, center, radius=1, color=color, thickness=-1)
cv2.imwrite(f"{superglue_path}/temp_vis_{index}.jpg", temp_vis)
pcd_model_keypoints = o3d.geometry.PointCloud()
pcd_model_keypoints.points = o3d.utility.Vector3dVector(Keypoint_3D_model)
pcd_model_keypoints.colors = o3d.utility.Vector3dVector([[0, 1, 0] for _ in range(Keypoint_3D_model.shape[0])])
print(len(pcd_model_keypoints.points))
o3d.io.write_point_cloud(f"{superglue_path}/keypoints_{index}.ply", pcd_model_keypoints)
f_json_data = open(os.path.join(superglue_path, f"model_info_{index}.json"), "w+")
json_saved_data = {}
json_saved_data["camera_param"] = cam_k.tolist()
json_saved_data["transform"] = np.eye(4).tolist()
json_saved_data["angle"] = 0.0
json_saved_data["mask_kernel_size"] = mask_kernel_size
json_saved_data["edge_kernel_size"] = edge_kernel_size
json_saved_data["use_edge"] = args.use_edge
json.dump(json_saved_data, f_json_data, indent=4)
f_json_data.close()
if args.multi_temp:
for index, angle in enumerate(args.angle):
project_pcd_to_rgb(superglue_path, superglue_path, angle, args.auto_scale, mask_kernel_size, edge_kernel_size, index+1, args.use_edge)
torch.cuda.empty_cache()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("data_dir")
parser.add_argument("--file_transfer", default=False, action="store_true")
parser.add_argument("--output_dir")
parser.add_argument("--auto_scale", type=float, default=0.1, help="scale for pcd to mask")
parser.add_argument("--use_depth", default=False, action="store_true")
parser.add_argument("--use_edge", default=False, action="store_true")
parser.add_argument("--edge_kernel_size", type=int, default=3, help="edge kernel size")
parser.add_argument("--mask_kernel_size", type=int, default=5, help="morphologyEx kernel size")
parser.add_argument("--multi_temp", default=False, action="store_true")
parser.add_argument("--angle", type=float, nargs="+", default=[90,180,270], help="Angle for rotation.")
args = parser.parse_args()
if args.file_transfer:
file_transfer(args)
else:
generate_superglue_template(args)(3)利用模板生成脚本,复制历史数据
- 在模板生成脚本的下载目录中,鼠标右键点击空白处,出现"右键菜单",在"右键菜单"中点击
在终端中打开,打开Windows PowerShell终端,如下图所示。
- 在终端执行
conda activate pickwiz_py39命令进入到 pickwiz_py39 环境,如下图所示。
- 终端进入到 pickwiz_py39 环境后,继续执行以下命令,可根据模板生成脚本的名称、要复制的历史数据时间戳的路径、输出保存路径修改以下命令。
python generate_prompt_superglue.py #调用Python脚本,可根据模板生成脚本的名称修改
"C:\Users\dex\kuawei_data\PickLight\20240617150557809" #要复制的历史数据时间戳的路径,可根据历史数据时间戳修改
--file_transfer --output_dir #文件传输和输出命令
"C:\Users\dex\Documents\PickWiz\new_project_22\superglue" #输出文件保存路径,可自行修改保存路径示例:PickWiz版本>=1.7.5,模板生成脚本的名称是 "generate_prompt_superglue.py";
要复制的历史数据的时间戳路径是 "D:\Pickwiz\new_project\data\PickLight\20250411144909289";
输出文件保存路径是"C:\Users\dex\Documents\PickWiz\new_project_1\data\PickLight"。
python generate_prompt_superglue.py #调用Python脚本“generate_prompt_superglue.py”
"D:\Pickwiz\new_project\data\PickLight\20250411144909289" #要复制的历史数据时间戳的路径
--file_transfer --output_dir #文件传输和输出命令
"C:\Users\dex\Documents\PickWiz\new_project_1\data\PickLight" #输出文件保存路径执行命令时修改脚本名称、历史数据时间戳路径、输出文件保存路径,如下图所示。
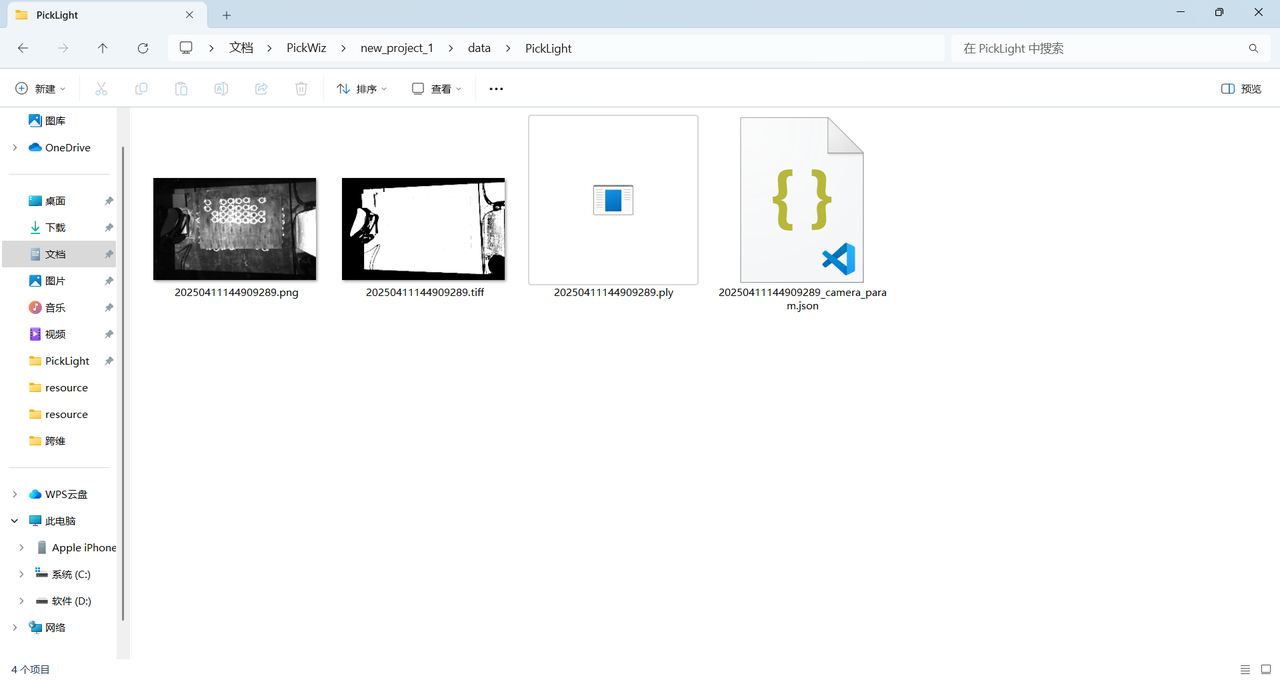
(4)执行完命令后,在保存路径下生成了4个文件,分别是场景的2D图像、场景的深度图、场景点云和相机内参
- 裁剪点云
在 meshlab 软件打开场景点云.ply文件,裁剪掉场景点云的噪点直至仅保留工件点云,然后直接点击覆盖保存。
裁剪点云时需要仔细保留完整的工件点云。
| 裁剪前 | 裁剪后 | 覆盖保存 |
|---|---|---|
 |  | 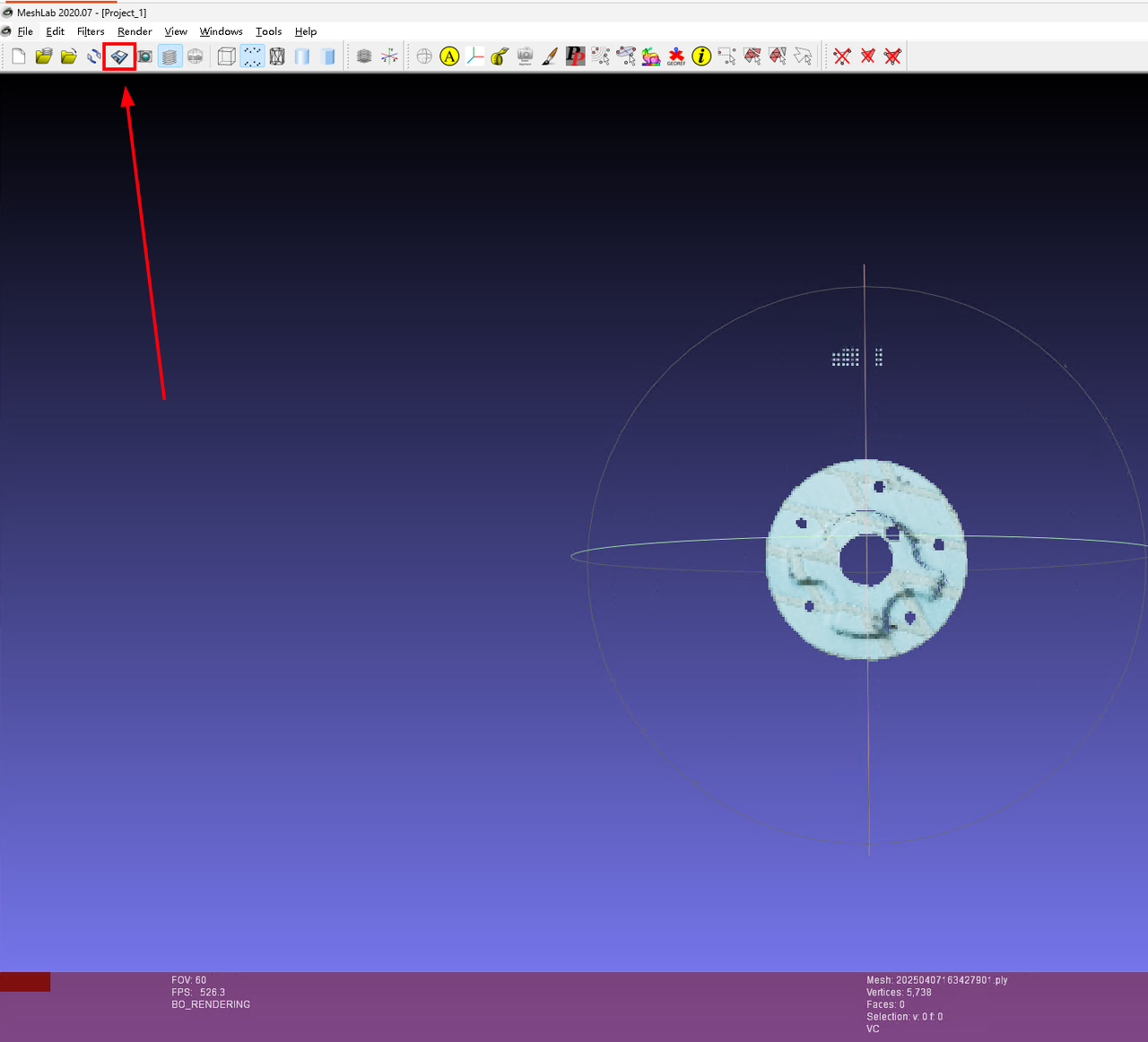 |
生成点云模板
在终端执行
conda activate pickwiz_py39命令进入到 pickwiz_py39 环境。
- 在 pickwiz_py39 环境下,执行如下命令,可根据工件特征修改以下命令。
脚本提供了--use_edge 、--multi_temp 参数,用于调整模板生成方式。 --use_edge 表示使用边缘检测,--multi_temp表示生成多方向模版用于来料方向不固定的场景。这两个参数默认不增加,表示不启用多模版和边缘检测,使用2D图生成点云模板。
当工件表面纹理不明显时,增加 --use_edge 参数,启用边缘检测强化图像特征,生成边缘增强的点云模板。
python generate_prompt_superglue.py #调用Python脚本
"C:\Users\dex\Documents\lixin\unify_infer\superglue_model_gen\superglue" #输入上面第3步的保存路径示例:当实际场景光照条件不稳定或工件表面纹理不明显、几何形状复杂时,可增加 --use_edge 参数,脚本会先对2D图像进行边缘检测,替代原本的2D图像进行匹配,匹配时会专注于工件的几何边缘特征,生成点云模板。
python generate_prompt_superglue.py #调用Python脚本
"C:\Users\dex\Documents\PickWiz\new_project_1\data\PickLight" --use_edge #输入上面第3步的保存路径,并且增加--use_edge边缘检测参数
- 执行指令后,在保存路径下生成了模板文件夹"superglue"。
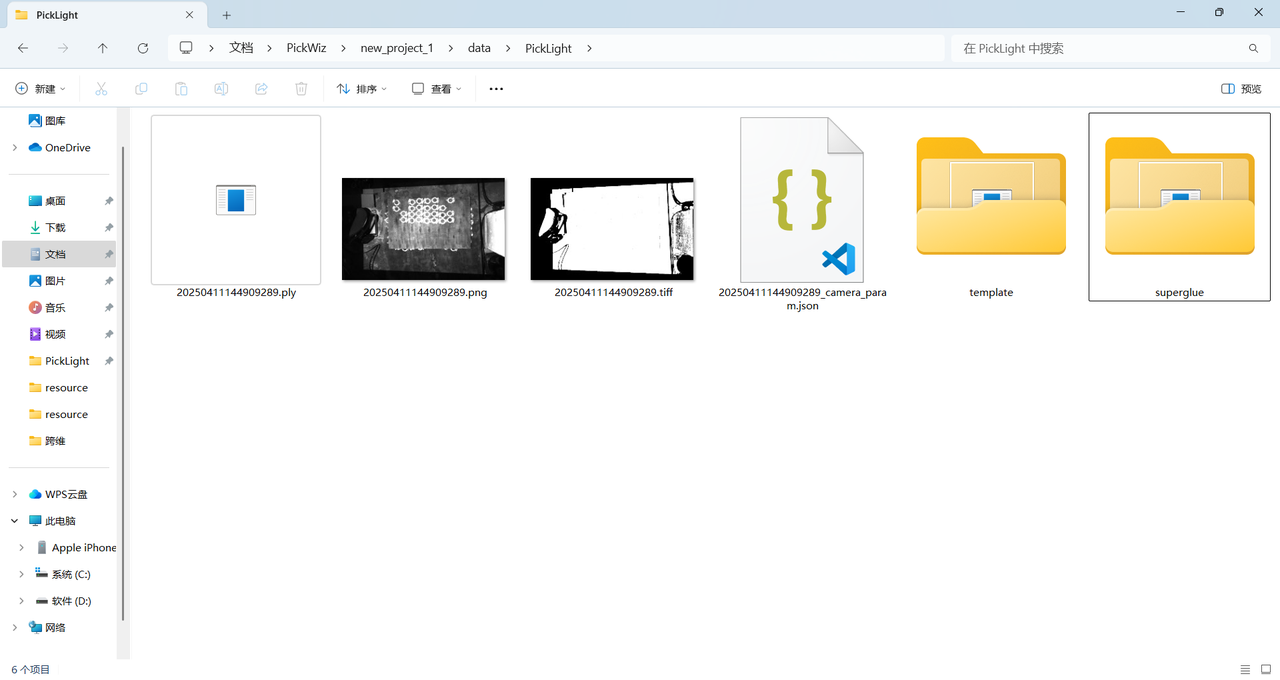
检查该文件夹下是否存在以下4个文件。
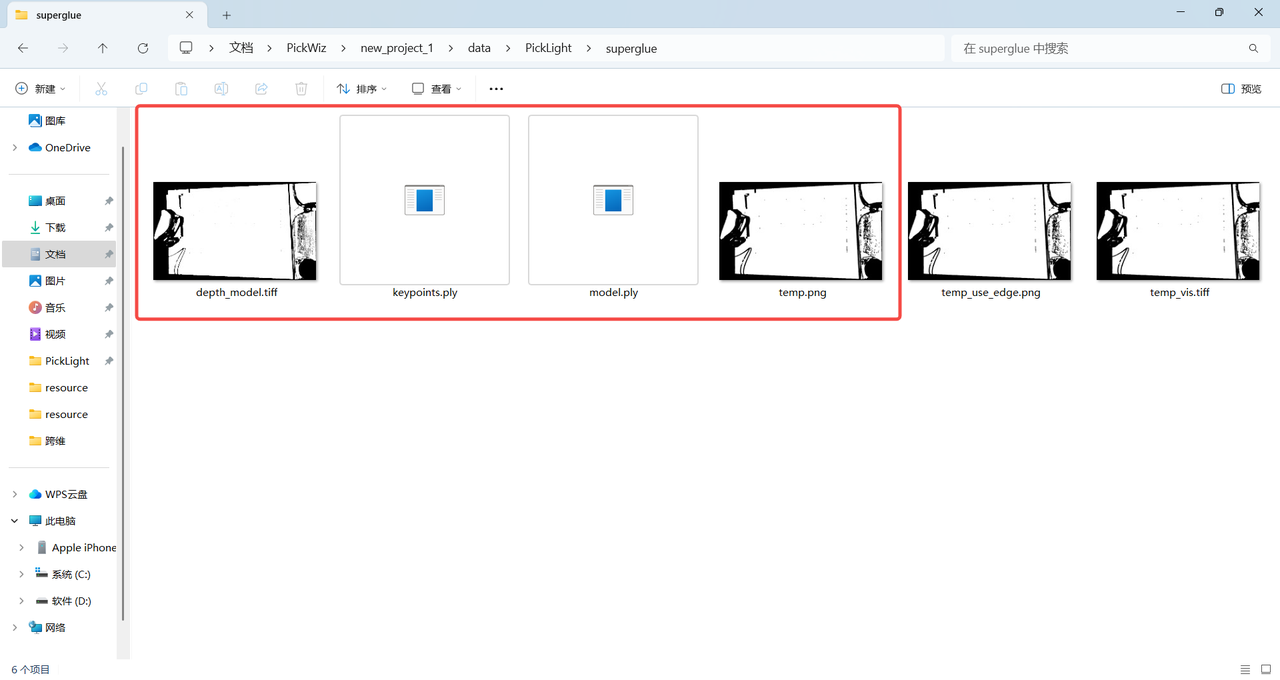
(注意灰度模式下模板图为灰度图,边缘模式下为二值图)
| 灰度模式 |  |
|---|---|
| 边缘模式 |  |
- 若来料包含多个方向,启用多模版方式的示例如下,其中
--angle后指定相对主模版的旋转角度,运行后会生成根据主模版旋转若干个角度的模版,如下所示
python generate_prompt_superglue.py superglue-compressor --use_edge --multi_temp --angle 45 90 180 225 270如下图所示

导入点云模板、选择模板文件路径
将保存路径下 "superglue"文件夹中的
model.ply文件作为点云模板导入到工件界面的点云文件中。
- 在
模板文件路径选择保存路径下"superglue"文件夹的路径(如C:\Users\dex\Documents\PickWiz\new_project_1\data\PickLight\superglue)。
- 模版生成脚本参数说明
| 参数名称 | 参数说明 | 取值建议 | 简单说明 |
|---|---|---|---|
| data_dir | 先验文件夹路径 | \ | 与先前生成数据脚本使用的文件路径一致windows复制路径为单反斜杠 “\”,报路径错误,需要将单反斜杠改为双反斜杠或改为取值建议中的正斜杠 “/” |
| file_transfer | 是否拷贝文件 | \ | \ |
| output_dir | 仅在 file_transfer 有效时起作用 | \ | \ |
| scale | 点云投影生成mask的缩放尺度 | 0.1 | 点云投影生成mask的缩放尺度 |
| use_edge | 是否启用边缘模式,不启用则为灰度模式 | \ | 多层堆叠时,下层物体与上层物体轮廓难以被模型区分,需使用灰度模式 |
| multi_temp | 是否生成多方向模版 | 默认为false,即默认仅生成单方向模版 | |
| mask_kernel_size | 点云投影成mask时的闭运算卷积核大小 | 5 | 使用默认值 |
| edge_kernel_size | 边缘特征提取时的卷积核大小 | 3 |  数值越大,特征图越靠内 数值越大,特征图越靠内 |
| angle | 多模版时,子模版相对主模版的旋转角度 | \ | 角度输入格式,可参考示例命令 |
2.2.2 匹配置信阈值(mm)

- 功能
特征点匹配的可信度分数,分数越高,特征点质量越高,但是匹配到的特征点数量可能越少
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
默认值:10
取值范围:[10, 800]
2.2.3 特征扩增数量

- **功能 **
在原始特征点检测的基础上人工扩增特征点数量,防止因特征点过少导致匹配异常。
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
默认值:3
取值范围:[0, 99]
2.2.4 特征扩增范围

- **功能 **
特征点扩增的选取邻域范围
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
默认值:3
取值范围:[0, 99]
- 调参:
当场景点云质量较好时可适当调大该参数,反之场景点云质量差时调小该参数
2.2.7 最大迭代次数

- **功能 **
限制算法在粗匹配阶段的最大迭代次数,避免因无限循环或收敛过慢导致计算资源浪费
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
默认值:100
不建议修改,后续会隐藏该函数
2.2.8 包围盒尺寸系数

- **功能 **
动态调整包围盒的尺寸,控制检测到的包围盒的长宽缩放比例。
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
默认值:1.0
- 调参
减少背景干扰或相邻目标的误合并,缩小检测范围,系数 <1.0;
防止目标部分(如遮挡)被裁剪,放大检测范围,系数 >1.0;
可根据2D识别结果中的包围盒情况调整该系数
2.2.9 启用深度特征

- **功能 **
通过 SuperGlue 模型提取的特征替代传统的点云特征,用于解决复杂场景下的匹配异常。
- 使用场景
面型工件有序上下料(并行化)场景
- 调参
适用于表面光滑、重复纹理、光照变化大的工件,适用于多类工件混合上下料
2.2.10 启用边缘特征

- **功能 **
启用时,仅在物体边缘区域提取和匹配特征点
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
物体边缘区域(如轮廓、锐利过渡区),忽略平坦或纹理单一的区域。
模板制作时也需同步启用use_edge,保证特征一致性。
2.2.11 粗匹配评判阈值(mm)

- **功能 **
特征点粗匹配时,仅保留可信度高于此值的匹配点。
- 使用场景
面型工件有序上下料(并行化)场景
- 参数说明
默认值:10
取值范围:[0.1, 1000]
- 调参
低阈值(如5):减少误匹配,但可能丢失有效点。
高阈值(如20):保留更多匹配,但噪声增加。
2.2.12 物体姿态修正
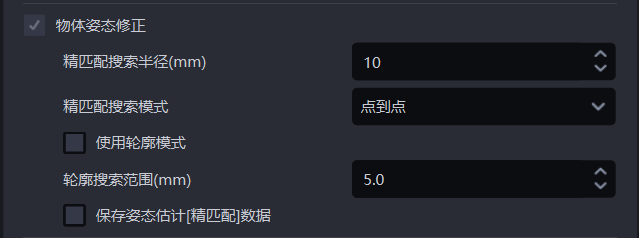
精匹配搜索半径(mm)

- 功能
在精匹配过程中,模板点云与实例点云进行匹配,模板点云中每个点都需要在实例点云中搜索最邻近点。精匹配搜索半径既表示在实例点云中的搜索半径,又表示模板点云中的每个点与实例点云中的最邻近点的距离阈值。若点与最邻近点的距离小于精匹配搜索半径,则认为这两个点能够匹配,否则认为两个点不能匹配。
- 使用场景
面型工件有序上下料、面型工件无序抓取、面型工件定位装配场景
- 参数说明
默认值:10
取值范围:[1, 500]
单位:mm
- 调参
通常不更改
精匹配搜索模式

- 功能
在精匹配过程中,模板点云在实例点云中检索最邻近点的方式
- 使用场景
模板点云与实例点云的精匹配效果不佳,应调整该函数
- 参数说明
| 参数 | 说明 |
|---|---|
| 点到点 | 模板点云中的每个点在实例点云中搜索最邻近点(搜索半径内直线距离最短的点)适用于所有工件 |
| 点到面 | 模板点云中的每个点沿着其法向量在实例点云中搜索最邻近点适用于几何特征明显的工件 |
| 点到点和点到面两种方式结合 | 先采用点对点模式优化实例点云中的工件姿态,再采用点对面模式优化实例点云中的工件姿态适用于几何特征明显的工件
|
使用轮廓模式

- 功能
提取模板点云和实例点云中的轮廓点云进行粗匹配
- 使用场景
面型工件有序上下料、面型工件无序抓取、面型工件定位装配场景,若使用关键点进行粗匹配的结果不佳,应当勾选该函数使用轮廓点云再次进行粗匹配
- 调参
粗匹配的结果会影响精匹配结果,如果精匹配结果不佳,可勾选 使用轮廓模式
轮廓搜索范围(mm)

- 功能
在模板点云和实例点云中提取轮廓点云的搜索半径
- 使用场景
通用工件有序上下料、通用工件无序抓取、通用工件定位装配场景
- 参数说明
默认值:5
取值范围:[0.1, 500]
单位:mm
- 调参
取值较小,搜索轮廓点云的半径较小,适合提取细致的工件轮廓,但提取的轮廓可能包含离群点噪声;
取值较大,搜索轮廓点云的半径较大,适合提取较宽的工件轮廓,但提取的轮廓可能会忽略一些细节特征。
保存姿态估计[精匹配]数据

- 功能
勾选则保存精匹配数据
- 使用场景
面型工件有序上下料、面型工件无序抓取、面型工件定位装配、面型工件定位装配(仅匹配)
- 示例
精匹配数据保存在项目保存路径\项目文件夹\data\PickLight\历史数据时间戳\Builder\pose\output文件夹中。
2.3 空ROI判断

- 功能
判断ROI 3D内是否还有工件(点云)剩余,如果ROI 3D内的3D点的数量小于该值,表示没有工件点云剩余,此时不返回点云
- 参数说明
默认值:1000
取值范围:[0, 100000]
- 使用流程
设置ROI 3D最小点数判断阈值,小于该阈值即ROI 3D中工件点云不足,从而判断为无工件在ROI 3D中;
机器人配置中,新增视觉状态码,便于后续机器人进行信号处理。